

오늘 교육에서는 AI 역사와 간단한 최신 용어에 대해서 배웠는데요.
오늘은 AI에서 주로 사용하는 단어를 알아보았습니다.
최근에는 파라미터만 키우는 게 아니라 효율화를 위한 노력이 많이 진행되는데요.
| 유형 | 핵심 원리 | 주요 아키텍처 특징 | 주요 사용 사례 |
비용/성능 프로파일
|
| LLM | 대규모 자기회귀 시퀀스 예측을 통한 범용 지능 | ㆍDecoder-only Transformer ㆍGQA ㆍTool-Use API |
복잡한 추론, 계획, 콘텐츠 합성 |
고비용, 고성능, 고지연
|
| LAM | 언어 이해와 실제 행동 실행을 상태 기반 루프로 연결 | ㆍReAct 프레임워크 ㆍ외부 메모리 ㆍ플래너 ㆍ도구 실행기 |
자율 에이전트, 워크플로 자동화 |
LLM 기반, 상태 관리에 추가 비용 발생
|
| MoE | 조건부 연산을 통한 대규모 파라미터 및 비용 효율성 확보 | ㆍ희소 활성화(Sparse Activation) ㆍ라우팅 네트워크 ㆍ전문가(Expert) FFN |
대규모 서비스 백엔드, 비용 효율적 추론 |
저비용, 고성능, 저지연 (활성 파라미터 기준)
|
| SLM | 모델 압축을 통한 엣지/온디바이스 환경 최적화 | ㆍPruning ㆍQuantization ㆍKnowledge Distillation |
온디바이스 비서, 실시간 UI, 프라이버시 중심 앱 |
초저비용, 중성능, 초저지연
|
| MLM | 양방향 문맥 이해를 통한 고품질 의미 표현 학습 | ㆍBidirectional Encoder ㆍContrastive Learning |
RAG 임베딩, 검색, 분류, 정보 추출 |
생성 불가, 임베딩 생성에 저비용/고효율
|
| VLM | 시각과 언어를 단일 End-to-End 모델로 통합 | ㆍ멀티모달 퓨전 ㆍVision Transformer + LLM |
멀티모달 문서 이해, 이미지 Q&A, OCR-free 처리 |
고비용, 복합적 성능, 파이프라인 대비 저지연
|
| LCM | 확산 모델 증류를 통한 실시간 고품질 이미지 생성 | ㆍLatent Space Consistency ㆍPF-ODE 해결 |
실시간 생성형 미리 보기, 인터랙티브 디자인 도구 |
생성 속도 수십 배 향상, 품질은 원본 대비 미세 저하 가능
|
| SAM | 프롬프트 기반 범용 제로샷 객체 분할 | ㆍViT 인코더 ㆍ경량 디코더 ㆍ스트리밍 메모리 (SAM 2.0) |
문서 레이아웃 분석, 비디오 객체 추적, 이미지 편집 |
분할 작업에 특화, 실시간에 가까운 속도
|
토큰
AI가 사용하는 최소 의미 단위
아래처럼 tokenized는 token + ized가 합쳐진거라 토큰이 2개로 나온다.
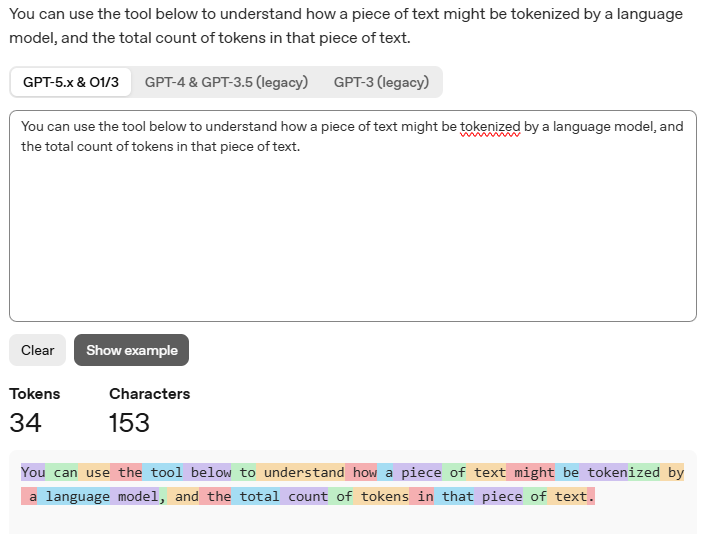
https://platform.openai.com/tokenizer
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.
platform.openai.com
MoE
Mixture of Experts(MoE)는 거대 언어 모델(LLM)에서 연산 효율성과 확장성을 동시에 달성하기 위해, 전체 매개변수 중 일부 전문가(서브 네트워크)만 활성화하는 "희소(Sparse) 모델" 방식입니다.
즉 각 요청별로 전체 파라미터를 활성화하여(통과시켜) 문장을 생성하는 기존의 방식에 대비해 일부의 파라미터만을 활성화하여 계산의 효율성은 높혀 빠른 응답이 가능하도록 했지만 적절한 파라미터 선택과정을 통해 생성된 문장의 질은 유지하는 특징을 갖고 있습니다. DeepSeek을 비롯하여 GPT-4, KIMI-2, Qwen3 등 최신 LLM 모델들이 모두 사용하고 있는 증명된 아키텍쳐입니다.
비용이 비싸기 때문에 새롭게 고민하고 있는 알고리즘입니다.
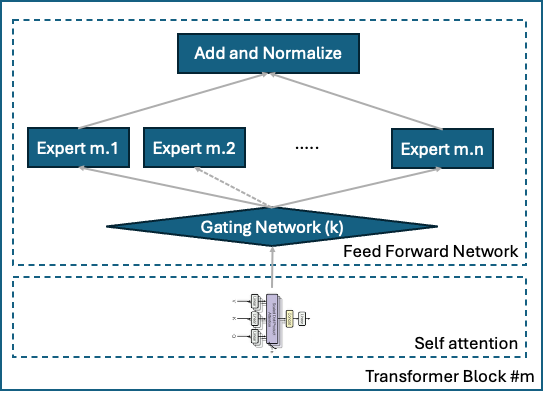
특히 딥시크는 전문가 기반 혼합(MoE, Mixture of Experts)이라는 기법을 사용하면서 효율화를 만든 것입니다. AI 모델을 여러 분야의 ‘전문가’로 구분한 뒤 질의가 들어오면 관련 분야의 전문가만 이용하는 식입니다. 딥시크의 기술보고서에 따르면 R1 모델의 파라미터(매개변수)는 6710억개 수준이지만 질문이 들어오면 340억개만 활성화하도록 만들어졌습니다. 일부 영역은 ‘공유 전문가’로 지정해 항상 활성화하고 기본적인 지식을 처리합니다. 기존 방식과 비교해 컴퓨팅 파워를 덜 쓰고 작업 속도도 빠르다는 장점이 있습니다.
SLM
SLM은 수억~수십억 개 수준의 파라미터로 구성된 경량화 모델로 특정 도메인 데이터에 기반한 고정밀 질의응답과 문서 요약, 분류, 해법 제시 등의 다양한 기능을 수행하는데요. 파라미터 수가 적어 메모리·연산 자원 소모가 많지 않은 데다가 응답 지연이 낮아 실시간 응용에 적합한 구조입니다.

그리고 이 SLM은 요즘 노트북에 들어가 있는 코파일럿AI 나 갤럭시에 들어가 있는 빅스비 등의 온디바이스 모델에서 사용합니다.
실제로 아래와 같은 사이트를 통해서 정리해볼수 있습니다.
Ollama
Ollama is the easiest way to automate your work using open models, while keeping your data safe.
ollama.com

프롬프트의 4대 구성요소
1. 역할 (Role) - "당신은 누구인가요?"
AI에게 특정한 페르소나를 부여하는 단계입니다. 전문가라는 인식을 심어주면 답변의 전문성과 톤앤매너가 확연히 달라집니다.
핵심 -"누구로 행동할까?"
예시 - "당신은 20년 차 브랜딩 전문가입니다.", "공감 능력이 뛰어난 SNS 컨설턴트로서 조언해 주세요."
2. 맥락 (Context) - "지금 어떤 상황인가요?"
AI가 상황을 오해하지 않도록 배경 지식과 정보를 주는 단계입니다. 구체적일수록 나에게 꼭 맞는 답변이 나옵니다.
핵심 - "어떤 상황에서, 누구를 대상으로?"
예시- "요즘 건강에 관심이 많은 40대 여성을 타깃으로 한 다이어트 시장에 대해 이야기할 거야."
3. 작업 (Task) - "무엇을 해야 하나요?"
수행해야 할 명확한 미션을 주는 단계입니다. 동사 위주의 명확한 지시가 필요합니다.
핵심 - "구체적으로 무엇을 해줄까?"
예시 - "트렌드 분석 보고서를 작성해줘.", "15초 분량의 숏폼 스크립트를 짜줘."
4. 형식 (Format) - "결과물을 어떻게 보여줄까요?"
답변을 받아볼 최종 형태를 지정하는 단계입니다. 내 업무 환경에 맞는 형식을 요구하세요.
핵심- "어떤 모양으로 출력해줄까?"
예시- 표(Table), 번호 리스트, 요약문, PPT 개요, 카드뉴스 형태 등

'Life > diary' 카테고리의 다른 글
| 충주맨 김선태 주무관 사직 (0) | 2026.02.18 |
|---|---|
| 설 연휴 여는 병원 약국 확인하기 (0) | 2026.02.16 |
| 토요일 여는 약국 종로 온유약국 후기(feat. 전자레인지) (2) | 2026.02.08 |
| 설날을 구정이라고 하면 안되는 이유 (0) | 2026.02.07 |
| 인간 VS 챗GPT 번역 블라인트 테스트 결과 공개 (0) | 2026.02.03 |