

파이썬에서 동적 페이지를 크롤링하려면 selenium이 필요한데요.
selenium이 없이 동적 페이지를 크롤링하는 방법을 알아보겠습니다.

동적 페이지란?
동적 페이지(dynamic website)는 기존의 정적 페이지(static website)의 반대말입니다.
정적 페이지는 실제로 서버에 페이지가 존재하는 형태입니다.
하지만 동적 페이지는 요청에 따라서 페이지를 그때그때 만들어서 제공하는 것입니다.

정적 페이지는 페이지를 보여줄 때 별도로 작업이 필요 없기 때문에 빠르다는 장점이 있고요.
다만 수정할 때에 직접 파일을 매번 수정해야 한다는 단점이 있습니다.
예를 들어 유튜브 페이지는 페이지를 아래로 내리더라도 실제 페이지 주소 등이 변하지 않는데요.
이러한 사이트를 동적 페이지라고 할 수 있습니다.
일반적으로 파이썬에서는 정적 홈페이지는 주로 requests나 urlib 패키지를 사용하고
동적 홈페이지는 selenium을 사용하는데요.

하지만 오늘 동적 페이지도 requests 패키지를 통해서 크롤링하는 방법을 알아보겠습니다.
동적 페이지 여부 확인하기
특정 페이지가 동적 페이지인지 여부는 크롬에서 F12 관리자 모드에 접속한 다음
Debugger에 있는 Disable JavaScript를 클릭하고
F5로 새로고침 하면 새로고침이 되지 않는다면 해당 페이지는 JS를 이용한 동적 페이지라고 할 수 있습니다.

해당 페이지를 javascripts를 비활성화한 다음 새로고침을 누르면
아래처럼 각각의 값이 JS문법으로 표시되고 동작하지 않음을 알 수 있습니다.
즉 HTML 페이지가 다 만들어진 파일이 아니라 JS를 통해서 요청 시마다 만들어진다는 것을 알 수 있습니다.

하지만 결국 JS를 이용하더라도 어떤 페이지가 만들어지기 때문에 해당 페이지 위치를 찾으면 되는데요.
다시 디버글러에서 Disable JavaScript 비활성화 한 다음
Network 메뉴에서 이제 불러오는 파일을 찾아야 합니다.
주로 Fetch/XHR에서 나오는데요.

Request URL에 실제 데이터가 되는 본문 파일이 있습니다.
일반적으로 content-type이 JSON인 파일을 찾으시면 되는데요.
Response Header가 Json이고 Request Url이 있는 걸 보니 잘 찾은 것 같습니다.
실제로 해당 주소를 파이썬으로 불러오니 아래와 같이 Json 파일로 구성되어 있음을 알 수 있습니다.

이제 원하는 부분을 크롤링하면 되는데요.
파이썬에서 JSON을 활용하는 방법은 저번에 적어 놓은 것이 있기 때문에 해당 기능을 활용하시면 됩니다.
json parser 등으로 원하는 부분을 확인하시면 되고요.
저는 viewcount를 불러오도록 하겠습니다. 보다 자세한 세부 기능은 저번에 포스팅한 것을 참고하시면 되겠습니다.

2022.06.16 - [Tip & Tech/Python] - 파이썬 공공데이터포털 API 연동하기 - JSON 사용
파이썬 공공데이터포털 API 연동하기 - JSON 사용
오늘은 파이썬으로 공공데이터포털 API와 연동하는 방법을 알아보겠습니다. 먼저 API가 무엇인지부터 알아보도록 하겠습니다. API(application programming interface)란? API는 컴퓨터와 컴퓨터간을 연결해
dorudoru.tistory.com
import requests
import json
from bs4 import BeautifulSoup
req = requests.get('사이트', headers={'User-agent' : 'Mozilla/5.0'})
html = req.text
data = json.loads(html)
data1 = data['blogPost']['viewCount']
print(data1)정말 간단하게 사이트에서 Viewcount 즉 조회수를 불러오는 것을 해보면 아래와 같이 코드를 짤 수 있고요.
파이썬으로 코드를 실행하면 아래처럼 221을 리턴하는 것을 알 수 있습니다.
여기서 특이한 점은 일반적으로 Beautifulsoup을 통해서 html 파싱을 하는데요.
지금은 텍스트가 json 방식이라 json.loads를 통해서 파일을 불러왔습니다.

제가 돌리면서 몇몇이 카운트되어 숫자가 일부 다르긴 하지만 정확하게 조회수를 긁어온 것을 알 수 있습니다.
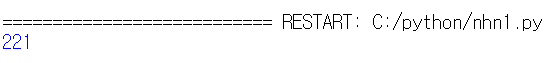
이런 방식으로 동적 웹사이트도 selenium 패키지가 아닌 requests 패키지로 찾을 수는 있는데요.
원하시는 방식에 따라서 사용하시면 될 것 같습니다.
'Tip & Tech > Python' 카테고리의 다른 글
| 최근 핫한 pynecone 프로젝트 후기 (29) | 2023.06.19 |
|---|---|
| 파이썬 유튜브 채널 50개 넘는 리스트 불러오기 (4) | 2022.08.11 |
| 파이썬 머신러닝 기초 - 결측치 처리하기 (6) | 2022.08.06 |
| 파이썬 크롤링시 날짜 에러 해결하기 (2) | 2022.08.02 |
| 파이썬 QR코드로 URL 링크 만드는 방법 (3) | 2022.07.23 |