

파이썬 머신러닝 기초를 한번 제가 공부하면서 정리하고 있습니다.

파이썬에서 머신러닝을 하기 위해서는 무엇보다 데이터 전처리가 중요한데요.
데이터 사이언티스트도 가장 많은 시간을 할애하는 작업은 데이터 전처리(cleaning and organizing data)입니다.

주요 내용은 Python 데이터 분석 실무 위키 북스를 참고하였습니다.
04-3. 데이터 전처리
모든 데이터 분석 프로젝트에서 데이터 전처리는 반드시 거쳐야 하는 과정이다. 대부분의 데이터 분석가가 좋아하지 않는 과정이지만, 분석 결과/인사이트와 모델 성능에 직접적인 ...
wikidocs.net
구글 코랩 설정하기
구글 코랩은 구글에서 지원하는 웹에서 python 스크립트를 작성하고 실행할 수 있는 툴입니다.
https://colab.research.google.com/?hl=ko
Google Colaboratory
colab.research.google.com
Colaboratory(줄여서 'Colab'이라고 함)을 통해 브라우저 내에서 Python 스크립트를 작성하고 실행할 수 있습니다.
구성이 필요하지 않음GPU 무료 액세스간편한 공유
학생이든, 데이터 과학자든, AI 연구원이든 Colab으로 업무를 더욱 간편하게 처리할 수 있습니다. Colab 소개 영상에서 자세한 내용을 확인하거나 아래에서 시작해 보세요.
먼저 구글 드라이브에서 파일연동이 가능하도록 구글 드라이브를 불러옵니다.
from google.colab import drive
drive.mount('/content/drive')

이후 연동이 되면 colaboratory에서 파일을 사용할 수 있습니다.
이후 원하는 파일에 우측 끝에 점세개를 누르고 경로복사를 합니다.

이후 해당 주소에 파일을 불러오시면 됩니다.
저는 df라는 변수에 csv파일을 하고 index_col=0 명령어를 통해서 기본으로 만들어지는 인덱스 열을 없앴습니다.
df = pd.read_csv('/content/drive/MyDrive/test/testset.csv', index_col=0)
그리고 df.head()를 통해서 데이터 값의 상태를 한번 살펴보았습니다.
그리고 이어서 df.info()를 통해서 데이터 상태를 한번 살펴봅니다.
숫자로 되어있는지 문자로 되어있는지, 각각 도메인의 상태를 확인합니다.

이후 결측치를 확인해야 하는데요.
결측치 확인하기
결측치는 isna()라는 함수로 확인할 수 있는데요.

전체 숫자만 보려면 뒤에 sum()함수를 추가해주면 됩니다.
df.isna().sum()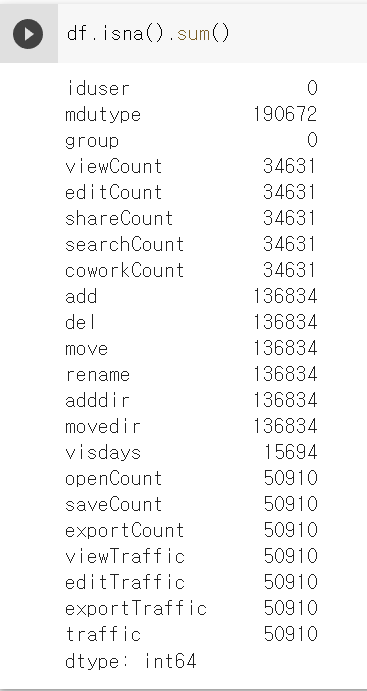
이제 이 결측치를 채워야 하는데요.
데이터 전처리 과정
먼저 데이터의 각각의 필드가 무엇을 뜻하는지, 그리고 중요한 필드가 어떤 것인지 정해야 합니다.
이 과정은 직관에 의한 것인데요.
그래서 데이터 전처리에 데이터 클리닝 및 전처리가 가장 오래 걸리기도 합니다.
이부분은 딥러닝으로 처리할 수 있는 부분이 아니기 때문이고,
또 전처리가 잘 되지 않으면 전혀 이상한 데이터가 나오기 때문입니다.
오래된 컴퓨터 용어인 GIGO처럼 처음부터 잘 정리된 데이터가 아니면
그 결과값 역시 신뢰하기 어렵기 때문입니다.

그래서 불필요한 필드는 아래처럼 drop시켜서 지우도록 합니다.
다만 작업전에 다시 파일을 불러오지 않도록 원본 df를 복사하여 주로 사용합니다.
혹시 데이터 조작하다가 원본데이터까지 날려버릴 우려가 있기 때문입니다.

함수 끝에 있는 inplace는 바로 적용하는 것입니다.
df1.drop("mdutype", axis=1, inplace=True)이후 결측치 처리를 하게 되는데요.
가장 쉬운것은 해당 결측치를 삭제하는 것이고, 일반적으로는 평균값 또는 앞뒤의 값을 사용하여 채우거나
이런 방식으로 처리합니다.
아래의 경우 전체의 값을 평균으로 대체하는 코드이구요.
일반적으로는 각각의 필드를 아래처럼 대체하거나, 또 문자열값인경우 문자열로 변경하기도 합니다.
#평균값으로 대체
df1['viewCount'].fillna(df1['viewCount'].mean(), inplace=True)
#문자열 변경
df1['gender'].fillna('M', inplace=True)
또한 이부분은 데이터 라벨링과 그 방향성이 유사한데요.
데이터 라벨링?
데이터 전처리 과정중 하나인데요.
데이터에 컴퓨터가 이해할수 있도록 라벨을 붙이는 작업입니다.
즉 강아지라는 데이터의 예시를 줘야 그 다음부터 컴퓨터가 자동으로 강아지와 고양이를 구별할 수 있는데요.

특히 이런 데이터 라벨링은 AI산업이 커지면서 점차 수요가 폭증하고 있습니다.

이 부분은 다음시간에 좀더 자세하게 알아보도록 하겠습니다.
'Tip & Tech > Python' 카테고리의 다른 글
| 파이썬 동적 페이지 selenium 없이 크롤링하기 (8) | 2022.08.19 |
|---|---|
| 파이썬 유튜브 채널 50개 넘는 리스트 불러오기 (4) | 2022.08.11 |
| 파이썬 크롤링시 날짜 에러 해결하기 (2) | 2022.08.02 |
| 파이썬 QR코드로 URL 링크 만드는 방법 (3) | 2022.07.23 |
| 파이썬으로 웹페이지 크롤링 후 글자수 세기 (2) | 2022.07.20 |