

안녕하세요. 오랫만에 파이썬 포스팅을 하게 되었네요.

오늘은 유튜브 페이지의 제목과 조회수를 크롤링 해보겠습니다.
유튜브 페이지 크롤링
저번에 포스팅과 같이 크롤링은 처음 구조 확인부터 시작되는데요.
유튜브 재생 플레이어의 경우 meta 정보에 포함되어 있습니다.
2021.02.17 - [Tip & Tech/Python] - 파이썬으로 네이버 스포츠 농구 일정 크롤링 하기
파이썬으로 네이버 스포츠 농구 일정 크롤링 하기
오늘은 파이썬을 이용해서 네이버 스포츠의 농구 일정을 크롤링 하는 프로그램을 짜보겠습니다. 먼저 오늘 크롤링 할 네이버 농구 일정 페이지입니다. 먼저 크롤링하기전에 주소를 찾습니다. sp
dorudoru.tistory.com
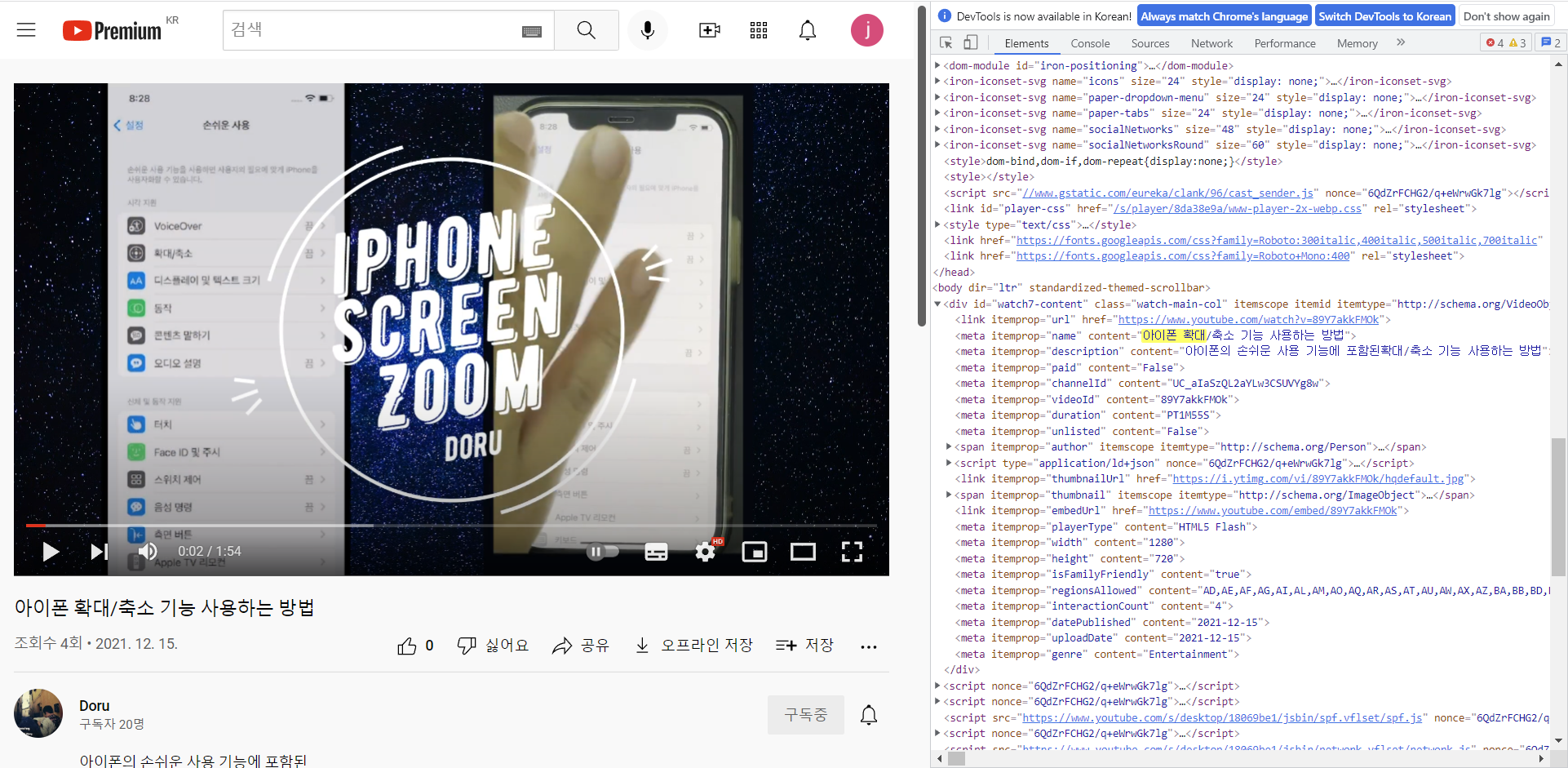
<meta itemprop="name" content="아이폰 확대/축소 기능 사용하는 방법"> 이렇게 제목이 있구요.
itemprop="duration" 재생시간
itemprop="interactionCount" 에는 조회수가 저장되어 있습니다.
간단하게 BeautifulSoup으로 찾고 select_one을 통해서 내용을 찾았습니다.
select_one은 딱 하나만을 찾아주는 함수입니다.
자세한 용법은 공식페이지를 참고하시면 됩니다.
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object, or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str() function returns a str
www.crummy.com
import requests
from bs4 import BeautifulSoup
doru = requests.get('https://youtu.be/UoRqHy07w8Q')
doru_text = bs4.BeautifulSoup(doru.text, 'lxml')
title = doru_text.select_one('meta[itemprop="name"][content]')['content']
view = doru_text.select_one('meta[itemprop="interactionCount"][content]')['content']
print(title)해당 기능을 업데이트 하기 위해서 CSV파일을 읽고 써서 하는 방식으로 변경해보았습니다.
먼저 원하는 주소를 url.csv 에 적어놓고, 파일을 읽습니다.
그리고 data라는 리스트에 저장합니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import csv
data = list()
f = open("c:/python/url.csv",'r')
rea = csv.reader(f)
for row in rea:
data.append(row)
f.close
yt_title = []
yt_view = []
time.sleep(0)
for i in data:
doru = requests.get(i[0])
doru_text = BeautifulSoup(doru.text, 'html.parser')
try:
title = doru_text.select_one('meta[itemprop="name"][content]')['content']
yt_title.append(title)
except:
title = i[0]
yt_title.append(title)
try:
view = doru_text.select_one('meta[itemprop="interactionCount"][content]')['content']
yt_view.append(view)
except:
view = '없음'
yt_view.append(view)
result = pd.DataFrame([yt_title,yt_view])
result.to_csv('c:/python/result.csv',encoding='euc-kr')이후 유튜브 제목과 조회수를 추출하여 yt_title, yt_view에 리스트로 저장한뒤
마지막은 to_csv를 통해서 result.csv로 출력하는 프로그램입니다.
다만 유튜브 링크중 짤린 것이 있어서 try와 except를 통해서 예외처리를 해주었습니다.
그리고 해당 코드를 셀레니움을 통해서도 가능한데요.
셀레니움 설치
먼제 Selenium을 쓰기 위해서는 먼저 설치를 해야합니다.
설치는 간단하게 pip install selenium 명령어를 통해서 할 수 있습니다.

셀레니움은 인터넷에 있는 코드를 활용해서
url.csv 파일에 있는 유튜브 주소를 불러와서 제목 조회수를 불러오는 형태로 만들어 보았습니다.
인터넷에 정말 잘 설명된 분들이 많아서 좋습니다.
import requests
import pandas as pd
import urllib.request
from bs4 import BeautifulSoup
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
url = pd.read_csv("c:/down/url.csv",encoding='utf-8')
print(url)
delay = 1
browser = Chrome('c:\down\chromedriver.exe')
browser.implicitly_wait(delay)
browser.get(url[0])
browser.maximize_window() #창 화면 키우기
body = browser.find_element_by_tag_name('body')
pages = 2
while pages:
body.send_keys(Keys.PAGE_DOWN)
time.sleep(1)
pages -= 1
soup = BeautifulSoup(browser.page_source,'html.parser')
# 제목, 조회수 조회
title = soup.select_one('meta[itemprop="name"][content]')['content']
print(title)
try:
view = soup.select_one('meta[itemprop="interactionCount"][content]')['content']
print(view)
except:
view = '없음'
print(view)
browser.close()그럼 잘 사용하시기 바랍니다.
'Tip & Tech > Python' 카테고리의 다른 글
| 파이썬 crontab으로 스케쥴링 하기 (16) | 2021.12.30 |
|---|---|
| 파이썬 유튜브 API 연동하기 (8) | 2021.12.30 |
| 파이썬 기초 문법 5일차 - 판다스 2편 (2) | 2021.09.07 |
| 파이썬 기초문법 4일차 - 판다스 알아보기 (4) | 2021.09.05 |
| 파이썬 기초 문법 3일차 - Numpy (4) | 2021.09.03 |