

오늘은 파이썬을 이용해서 네이버 스포츠의 농구 일정을 크롤링 하는 프로그램을 짜보겠습니다.
먼저 오늘 크롤링 할 네이버 농구 일정 페이지입니다.
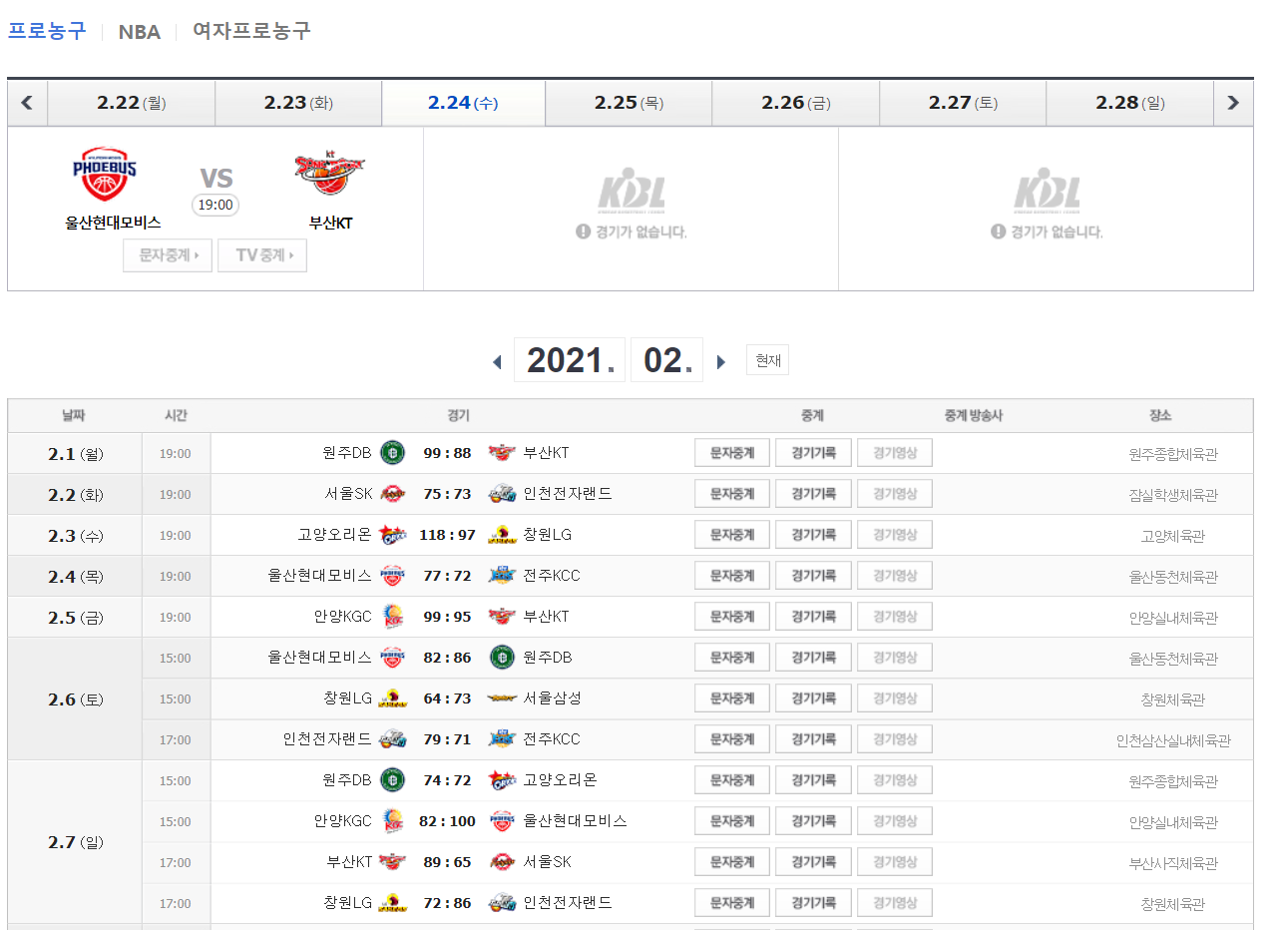
먼저 크롤링하기전에 주소를 찾습니다.
그리고 사이트구조를 크롬의 f12키를 통해서 찾아봅니다.
경기 일정은 DIV로 묶여져 있는데요.

치사하게 div class를 두개로 구분해놨습니다. class가 sch_tb와 sch_tb2로 구분되어 있습니다.

일단 여기까지 크롤링하는 프로그램을 짜보면,
bs4, request, 저장하기 위해서 pandas를 부르구요
from bs4 import BeautifulSoup
import requests
import pandas as pd
address = "https://sports.news.naver.com/basketball/schedule/index.nhn?date=20210224&month=02&year=2021&teamCode=&category=kbl"
request = requests.get(address)
html = request.text
soup = BeautifulSoup(html, 'html.parser')
soupData = [soup.findAll("div", {"class" : "sch_tb"}), soup.findAll("div", {"class" : "sch_tb2"})] #sch_tb랑 tb2둘다 저장주소를 적고 request를 통해서 불러옵니다.
soup를 통해서 html을 구분하구요.
findAll을 통해서 class가 sch_tb, sch_tb2인 것을 모두 불러옵니다.
여기까지 실행을 해서 print 해보면 제가 원하는 부분을 파싱해 왔음을 알 수 있습니다.

이제 개별 항목들을 불러와야 하는데요.
항목중에 rowspan이 정의되어 있습니다. 이게 하루에 있는 경기 수인데요.
1이면 그날 한경기 3이면 그날 3경기, 4이면 4경기, 5면 경기가 없는날입니다.

이에 따라서 분기가 생겨야 겠네요. rowspan이 5인경우에는 남자프로농구 경기가 없습니다라고 표시됩니다.

실제로 웹브라우저에서도 이렇게 보여집니다.

그리고 각각의 변수를 찾으면 되는데요. 각각의 변수는 아래와 같습니다.
|
td_date = 경기일 |
그러면 나머지 코드는 이를 따라서 코딩하면 됩니다.

그리고 마지막 출력은 판다스로 DataFrame을 만들어서 출력하면 됩니다.
저는 아래와 같은 방식으로 출력하였습니다.
df = pd.DataFrame(dataList) #pandas로 출력
df.T.to_csv('basket.csv', encoding='cp949') #csv파일 출력 실제 2월 전체 출력하면 아래와 같습니다.
그럼 잘 사용하시길
'Tip & Tech > Python' 카테고리의 다른 글
| 파이썬 기초 문법 3일차 - Numpy (4) | 2021.09.03 |
|---|---|
| 파이썬 기본 문법 강의 2일차 - 제어문으로 로또 게임 만들기 (8) | 2021.09.02 |
| 파이썬 기본 문법 강의 - 1일차 (9) | 2021.09.01 |
| 파이썬으로 네이버 웹툰 웹크롤링 하기 (0) | 2021.04.05 |
| [Python] 디시인사이드 갤러리 웹 크롤링하기(1부) (0) | 2020.11.19 |