

안녕하세요. 오늘은 파이썬을 활용해서 네이버 웹툰 사이트를 웹크롤링 하는 방법을 알아보겠습니다.
웹크롤링 단계
사실 웹크롤링은 웹페이지의 가져와서 데이터를 추출해 내는 것인데요.
나무위키에 따르면 아래와 같다고 합니다.
| 크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부른다. |
저와 같은 초보일수록 기초적인 실수를 안하려면 단계를 정하고
그에 따라서 코딩하는 것이 시행착오를 줄일 수 있습니다. 저는 일반적으로
- 크롤링하려는 페이지 구조확인 및 크롤링하고자 하는 위치파악
- 코딩 및 필요한 내용 구글링
- 테스트 및 디버깅
위와 같은 순서로 짜고 있는데요.
이에 따라서 포스팅 해보겠습니다.
크롤링 페이지 구조 확인 및 위치파악
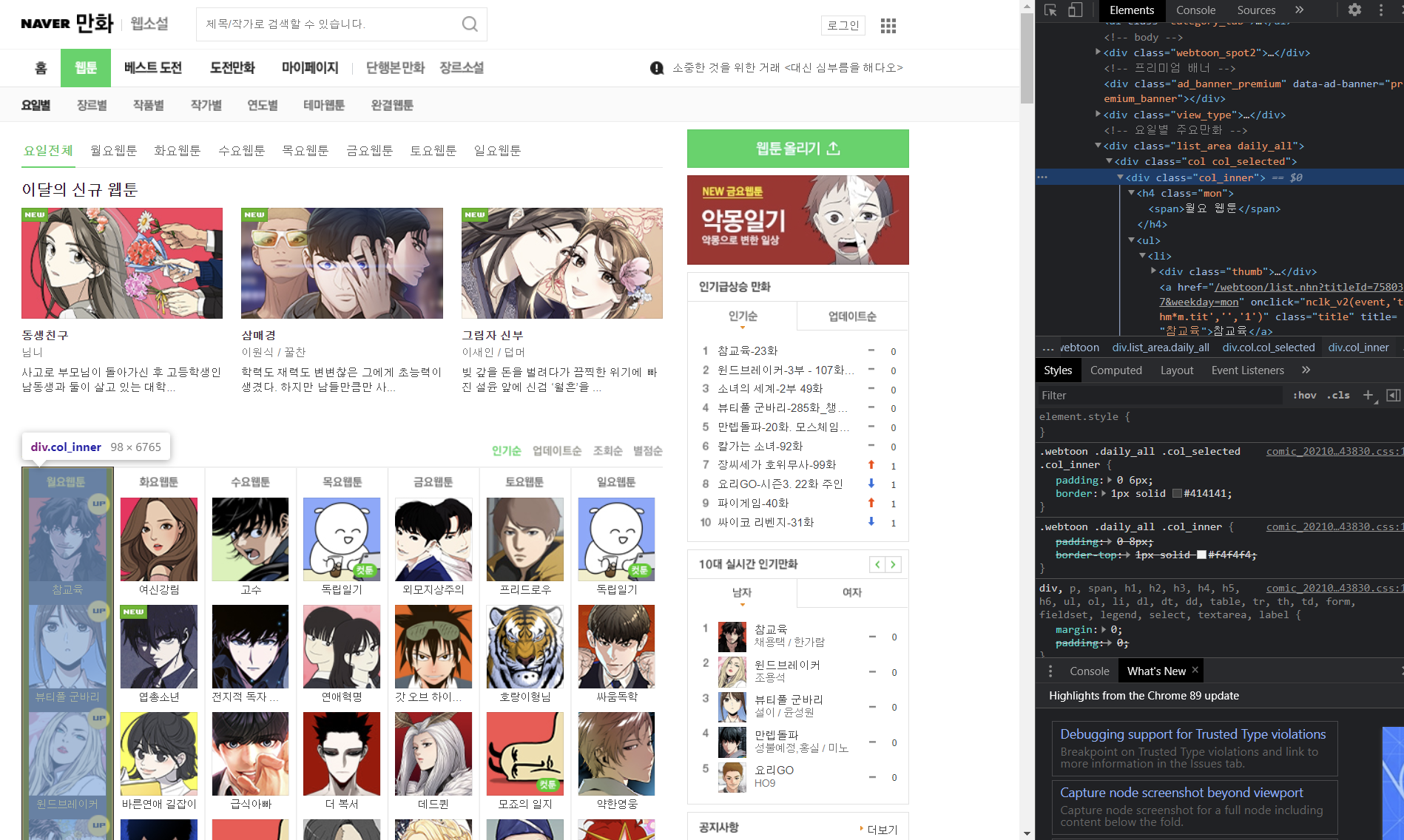
먼저 오늘 크롤링하려고 하는 네이버 웹툰 페이지를 확인해봅니다.
크롬의 F12에서 나오는 개발자 도구로 진행할 예정입니다.
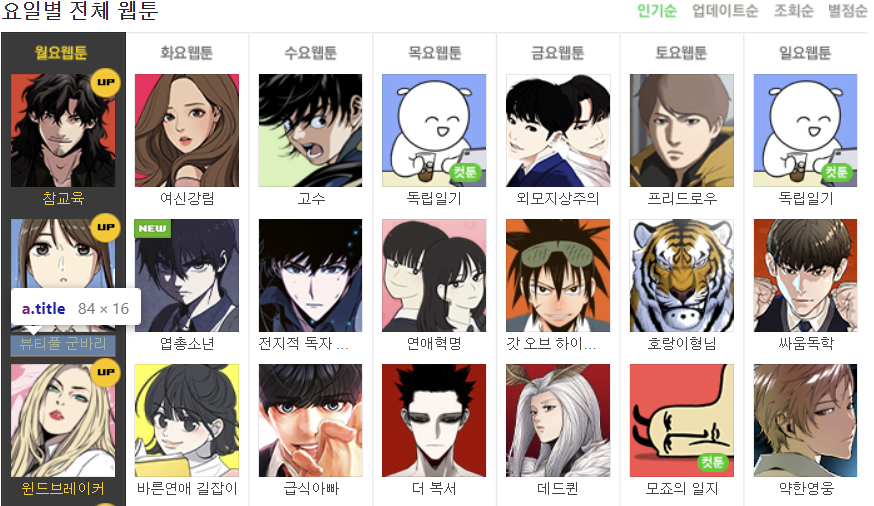
저는 요일별 웹툰 리스트를 크롤링 해보려고 하는데요.
아래처럼 div 아래에 col_inner로 묶여 있음을 알 수 있습니다.
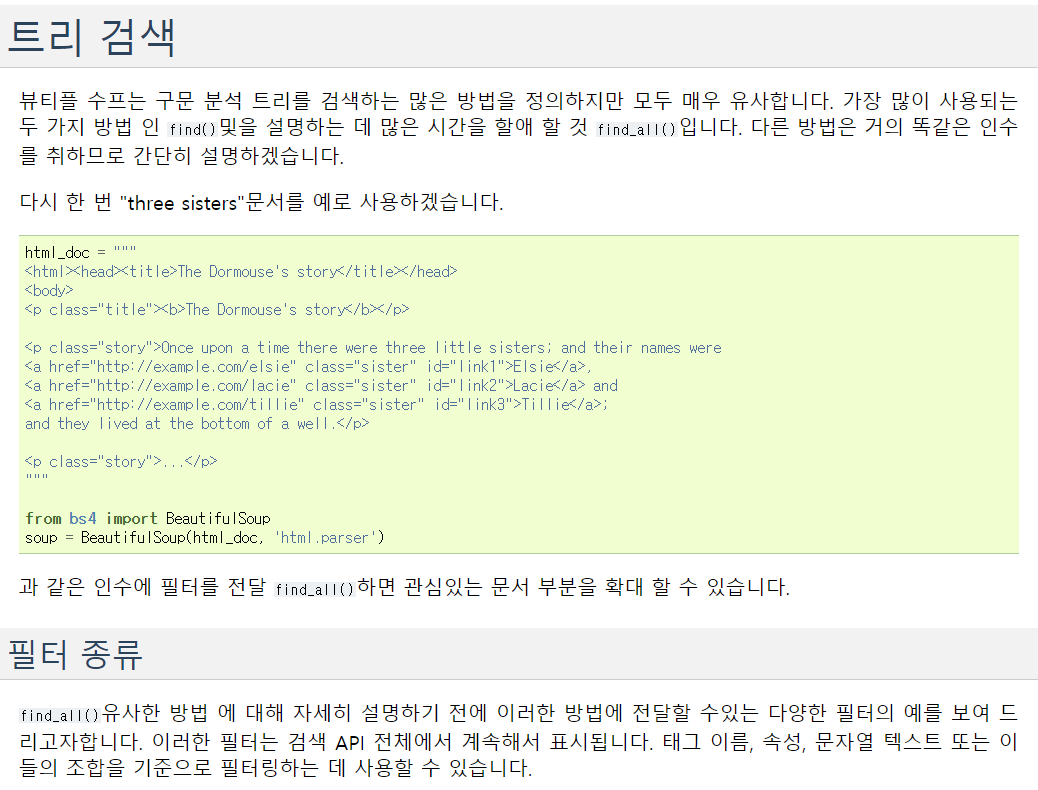
그리고 이 내용을 긁어오는 건 파이선의 beautifulsoup4를 통해서 할것인데요.
www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object (unicode() in Python 2), or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str(
www.crummy.com
Document를 통해서 find_all 또는 select를 통해서 원하는 내용을 선택할 수 있습니다.
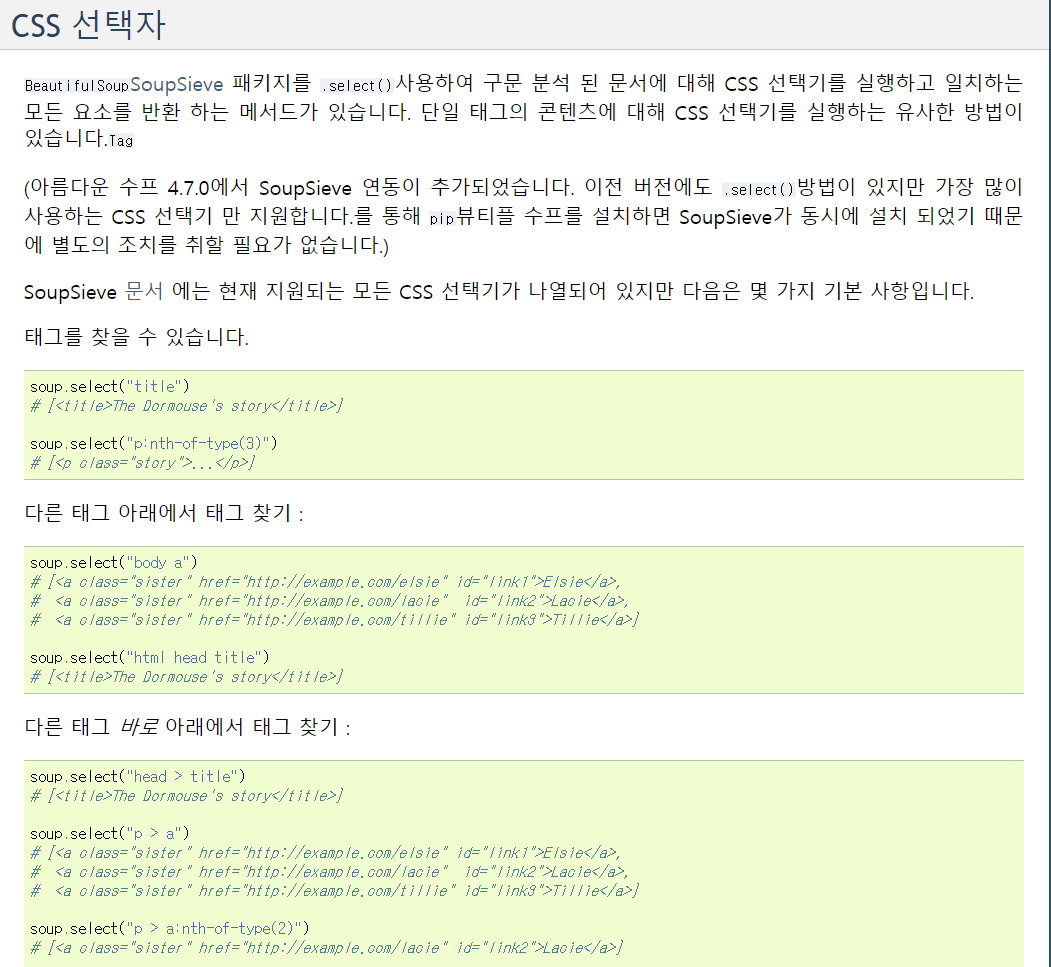
코딩하기
import requests
from bs4 import BeautifulSoup
wt_url = 'https://comic.naver.com/webtoon/weekday.nhn'
response = requests.get(wt_url)
soup = BeautifulSoup(response.text, 'html.parser')
raw_title_list = soup.select('a.title') #title칸의 값 모두 긁어오기
title_list = []
i= 1
for a in raw_title_list: #타이틀 전체를 불러와서 정렬
a_href = a.get('href')[-3:] #주소에서 마지막 3자리가 요일
a_text = a.get_text() #제목파일 가져옴
if a_href == 'tue': #요일에 맞춰서 동작
result = f'{i:2d}위 {a_text}'
title_list.append(result)
i+=1
else: #예외조건 실행
continue
print('\n'.join(title_list))
전체코드는 위와 같습니다.
제목은 a.title로 불러왔구요. select를 통해서 선택했습니다.
요일 소스는 a href에 마지막 3자리가 mon임을 활용해서 작성했습니다.
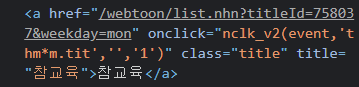
a_href = a.get('href')[-3:] #주소에서 마지막 3자리가 요일
그래서 if 문으로 특정요일일때만 동작하도록 만들어 놨구요.
코드 실행 테스트
실제 실행하면 정상적으로 동작함을 알 수 있습니다.
요일을 바꿔가면서도 테스트 해봅니다.

아래 사이트에서도 잘 설명해놨기 때문에 참고하셔서 스크랩하시면 될것 같습니다.
아래 3곳의 사이트를 참고하여 만들었습니다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
BeautifulSoup, find와 select 를 사용한 웹 크롤링
파이썬을 배우고 몇 번 웹 스크레핑 (웹 크롤링)을 해보니 웹 스크레핑의 기본 프로세스는 대개 정해진 패턴이 있다는 것을 알게 되었습니다. 따지고 보면 웹 스크레핑이라는 것은 웹페이지에서
smorning.tistory.com
네이버 웹툰 크롤링 프로젝트
requests와 BeautifulSoup을 이용해서 네이버 웹툰 메인 페이지에 존재하는, 모든 웹툰의 제목과 링크를 크롤링합니다.
velog.io
'Tip & Tech > Python' 카테고리의 다른 글
| 파이썬 기초 문법 3일차 - Numpy (4) | 2021.09.03 |
|---|---|
| 파이썬 기본 문법 강의 2일차 - 제어문으로 로또 게임 만들기 (8) | 2021.09.02 |
| 파이썬 기본 문법 강의 - 1일차 (9) | 2021.09.01 |
| 파이썬으로 네이버 스포츠 농구 일정 크롤링 하기 (9) | 2021.02.17 |
| [Python] 디시인사이드 갤러리 웹 크롤링하기(1부) (0) | 2020.11.19 |