

오늘은 4일차 파이썬 강의 판다스를 알아보겠습니다.

Pandas란?
판다스는 파이썬에서 데이터 구조 및 데이터 구조를 분석할 수 있는 오픈소스 라이브러리 입니다.
pandas - Python Data Analysis Library
pandas pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language. Install pandas now!
pandas.pydata.org
특히 많은 파이썬 프로그램의 기본이라고 할 정도로 많이 사용되고 있고,
SQL 및 EXCEL, 시계열 및 다양한 데이터를 작업할 수 있습니다.
판다스의 기본적인 자료 구조는 Series와 DataFrame으로 이루어져 있는데요.
대소문자 구별해야하니 조심해서 사용하시기 바랍니다.

위의 자료구조 처럼 간단하게 데이터를 만들고 확인할 수 있습니다.
먼저 설치하려면 pip install pandas로 라이브러리 설치하고
import pandas as pd로 모듈을 불러와야 합니다.
아래는 numpy를 활용해서 100~105까지 숫자를 만들고 float32실수로 시리즈를 만드는 예시입니다.

판다스에서는 결측치(NaN)이 존재하는데요.
isnull, isna를 통해서 결측치를 찾고 notnull,notna는 결측치가 아닌 값을 찾습니다.
무엇보다 가장 유명한 타이나틱 데이터를 통해서 자료를 찾아보겠습니다.
위의 타이타닉 링크에서 다운로드 받아도 되고 케글에서 받은 타이타닉 파일을 업로드 하셔도 됩니다.
https://www.kaggle.com/c/titanic/
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
판다스에서 데이터를 불러오려면
read_csv 또는 read_excel을 통해서 파일을 불러올 수 있습니다.
그리고 코랩에서는 아래의 file.upload를 통해서 파일을 업로드할 수 있습니다.
아니면 seaborn이 제공하는 타이타닉 데이터를 사용해도 됩니다.
TRAIN_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/train.csv"
df = pd.read_csv(TRAIN_DATA_URL)
from google.colab import files
uploaded = files.upload()
df = sns.load_dataset('titanic')
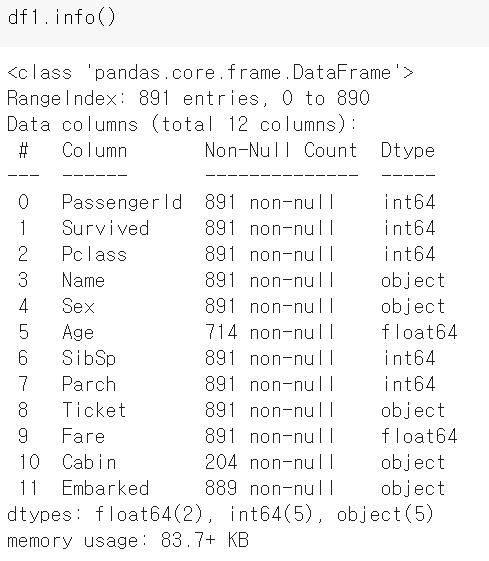
불러온 데이터를 먼저 살펴봅니다. df1.info를 통해서 데이터를 살펴보고
결측치도 isna()를 통해 알아봅니다. 뒤에 sum까지 붙이면 간단하게 결측치 갯수가 확인 가능합니다.

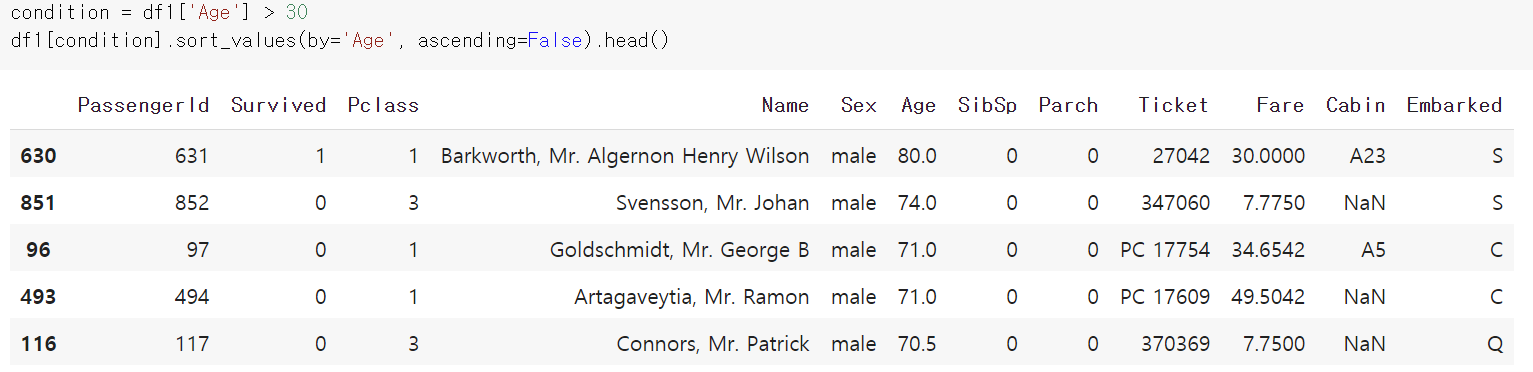
그리고 이런 데이터는 조건을 줘서 볼수 있는데요.
condition을 나이로 30살 이상으로 설정하고 나이순 내림차순으로 정렬하면 아래와 같습니다.
sort_values는 값을 정렬을 하는 것이고, sort_index를 통해서는 인덱스기준으로 정렬이 가능합니다.
정렬할 항목은 by다음에, 그리고 정렬 순서는 ascending을 통해서 설정합니다.
그리고 데이터는 value_count()를 통해서 값의 분포를 확인할 수 있습니다.
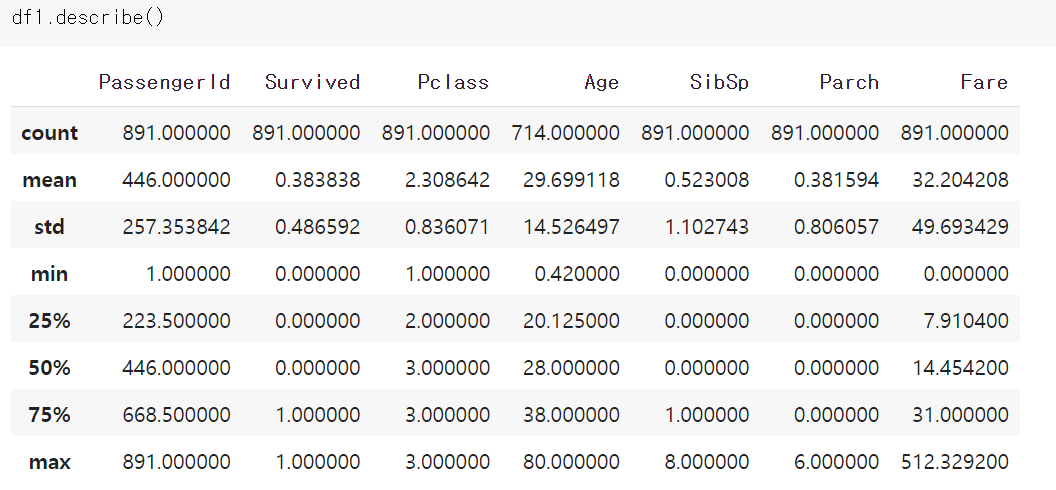
그리고 describe를 치면 각각의 갯수, 평균, 최소 최대 값등을 한눈에 확인 할 수 있습니다.

그리고 데이터 타입 변환은 astype명령어를 통해서 변경할 수 있습니다.

그리고 이제 판다스에서 가장 중요한 건 데이터 선택인데요.
loc을 통해서 데이터를 선택할 수 있습니다.
아래와 같이 기존의 list에서 [1][1]을 통해서 선택하던 것을 loc[1 , 1]로 선택할수 있고
나아가 범위를 선택할 수 있습니다. 그리고 여기에 조건을 줘서 선택도 가능합니다.


사실 판다스 튜토리얼에도 잘 나와있는데요.
새로운 열 추가역시 간단합니다.
test['Multi]라는 열을 추가해봤는데요.
test의 3번째 열을 2배로 곱해서 만들었습니다.

그리고 엑셀의 피벗테이블과 같은 기능을 수행할 수도 있는데요.
groupby라는 함수를 사용할수 있습니다.
남녀의 나이 평균을 알아보는 함수는 아래처럼 구할 수 있습니다.
df.groupby('sex').mean()
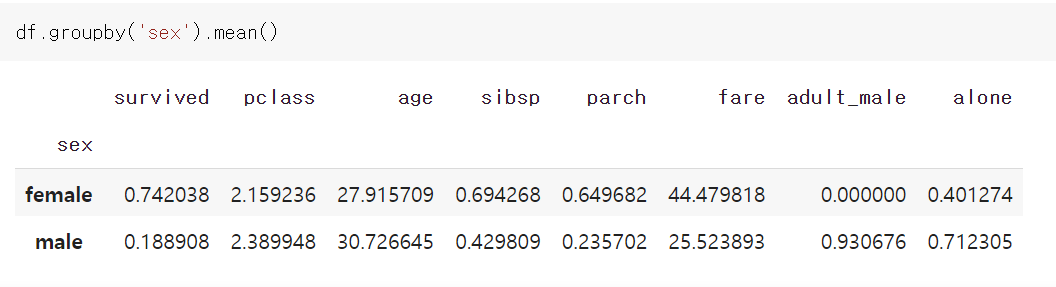
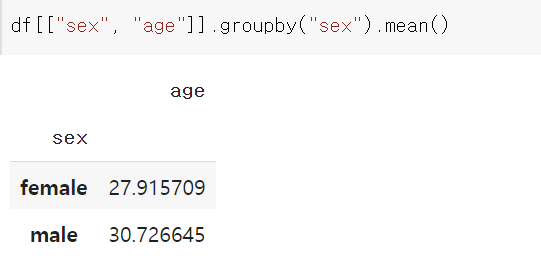
여자의 생존확률이 높네요.
간단한 명령어들을 실제 쳐보면서 판다스 기초 문법을 알아보았는데요.
다음 시간에는 좀더 다양한 방법을 알아보도록 하겠습니다.
'Tip & Tech > Python' 카테고리의 다른 글
| 파이썬 유튜브 제목, 조회수 크롤링하기 (6) | 2021.12.28 |
|---|---|
| 파이썬 기초 문법 5일차 - 판다스 2편 (2) | 2021.09.07 |
| 파이썬 기초 문법 3일차 - Numpy (4) | 2021.09.03 |
| 파이썬 기본 문법 강의 2일차 - 제어문으로 로또 게임 만들기 (8) | 2021.09.02 |
| 파이썬 기본 문법 강의 - 1일차 (9) | 2021.09.01 |