

드디어 길었던 코세라 강의가 끝났다.
주로 한글 캡션에, 영자막으로 계속 보면서 진행했습니다.
한글 자막이 구글 번역기에 돌린 품질로 ㅠㅠ
컴퓨터 용어의 해석이(?) 너무 잘못된 게 많아서 한글로만 보면 어려운 점이 많았다는 것 .
5주차와 6주차는 XML(Extensible Markup Language)와 JSON( JavaScript Object Notation)에 대해서 배우게 됩니다.
XML은 W3C에서 개발된, 다른 특수한 목적을 갖는 마크업 언어를 만드는데 사용하도록 권장하는 다목적 마크업 언어이다. XML은 SGML의 단순화된 부분집합으로, 다른 많은 종류의 데이터를 기술하는 데 사용할 수 있다.
JSON(제이슨[1], JavaScript Object Notation)은 속성-값 쌍( attribute–value pairs and array data types (or any other serializable value)) 또는 "키-값 쌍"으로 이루어진 데이터 오브젝트를 전달하기 위해 인간이 읽을 수 있는 텍스트를 사용하는 개방형 표준 포맷이다.
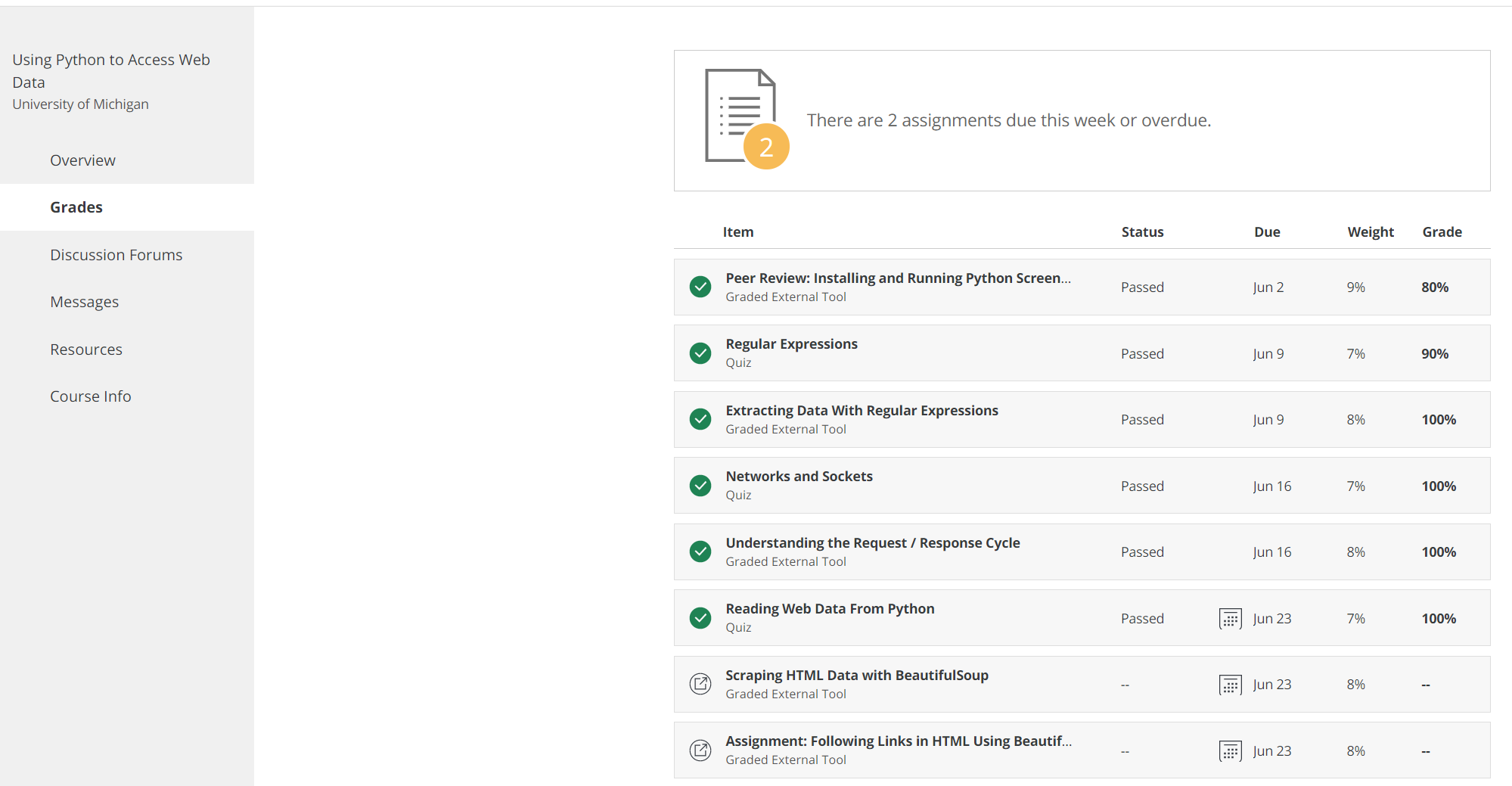
그리고 퀴즈 2개와 과제를 끝내면, 아래처럼 드디어 과정이 끝나게 된다.

과정이 끝나면 아래처럼 소정의 인증서를 준다.

그리고 지금까지의 과정의 점수를 보여줍니다 ㅎㅎ
생각보다;; 초반에 헤메가지고 많이 틀렸네요.
5장과 6장의 과제는 거의 비슷한데요.
XML을 elementtree를 사용하고 Json은 Json만 사용한다는 점이 좀 차이가 있습니다.
기본적으로 하나 변수를 읽고 하나 변수를 바로 Print해서 보시면서 하나하나 풀면 어느 정도 감이 오실 것 같습니다.
import urllib.request, urllib.parse, urllib.error
import xml.etree.ElementTree as ET
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter location: ')
tn = 0
x = 0
print('Retrieving', url)
# 입력주소 실행
uh = urllib.request.urlopen(url, context=ctx)
# 열린 파일 읽기
xml = uh.read()
# xml에서 스트링 읽기
tree = ET.fromstring(xml)
# 불러온 것에서 아래 배열로 두 번 내려가서 count 모두 찾기
counts = tree.findall('.//count')
# 합계(x는 count.txt 숫자 더하고, tn는 전체 반복횟수 더함)
for count in counts:
x += int(count.text)
tn += 1
print('Count:', tn)
print('Sum:', x)
< 후기 >
언어의 장벽이 가장 아쉬움 ㅠ
한글로 된 과정이었으면 좀더 잘 듣지 않았을까 생각함 ㅎㅎ
그리고 이게 중급과정이다 보니, 초보자인 내가 듣기에는...
생략된거 찾기가 쉽지는 않았다는점..
그래도 바로바로 웹페이지에서 긁어서 결과 보는것은 재미있었음 ㅎ
'Work' 카테고리의 다른 글
| [꿀팁] 은행을 안 가고도 통장 사본 만드는 방법 (0) | 2019.09.14 |
|---|---|
| [카카오뱅크] 동호회 모임통장 만들기 (0) | 2019.09.10 |
| [Coursera] Access to Web data week 4 (0) | 2019.06.21 |
| PP카드 - 기업은행 블리스7카드 (0) | 2019.06.21 |
| 온라인 마케터로 살아남기 - 2. 구글 닥스 결과 개인정보 정리하기 (0) | 2019.05.18 |