

요즘 듣고 있는 코세라의 Access to web data.
다만 인터넷에 돌아다니는 솔루션이 오래되서 ㅠㅠ
4주차부터 엄청난 위기가 도래했다.
사실 프로그래밍을 많이 하신분이라면 껌이겠지만.. 초심자에게는 너무나 가혹한 것
문제는 아래와 같다. span을 다 카운터해달라는 것
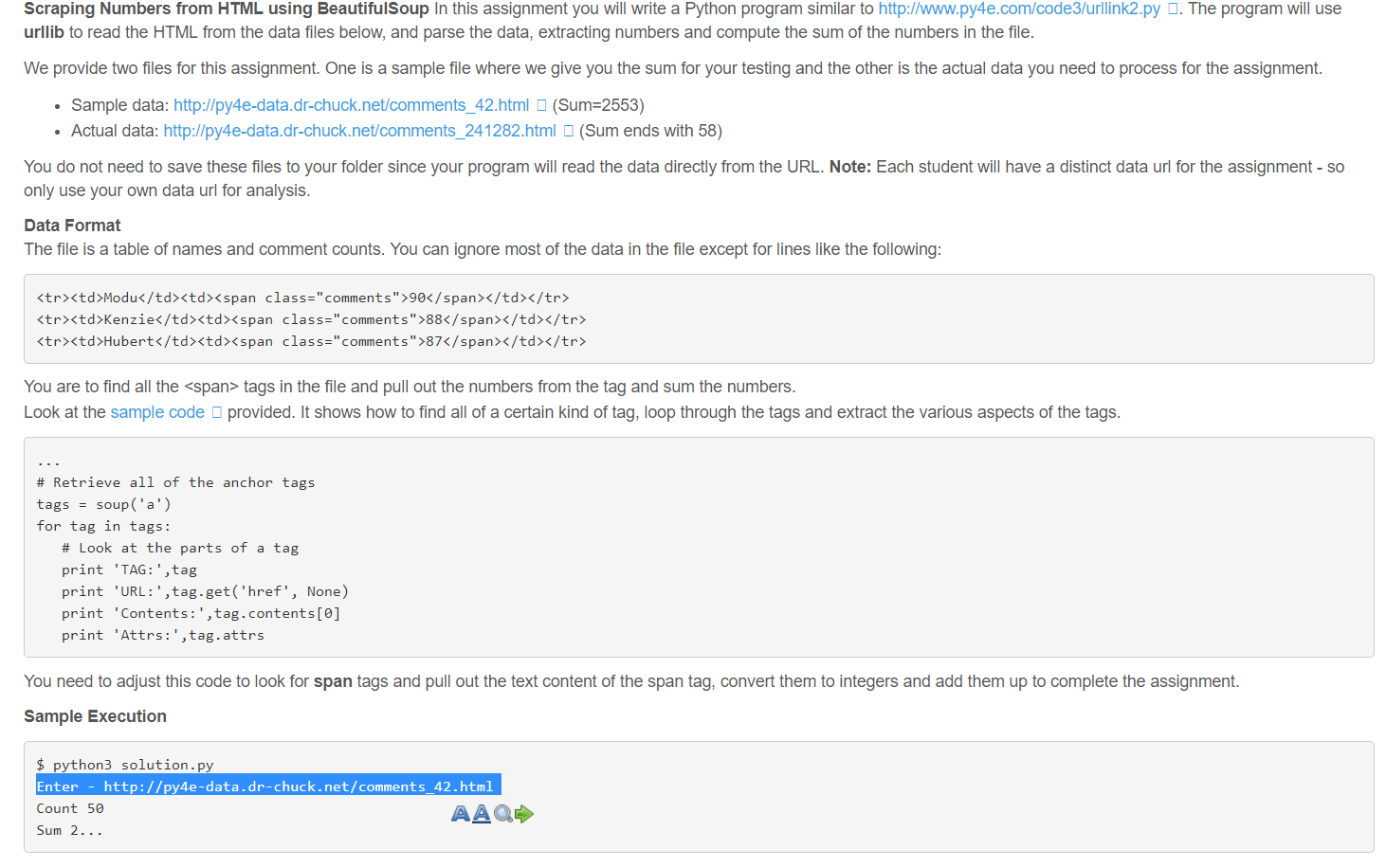
예제 파일을 한번 보자.
# To run this, you can install BeautifulSoup # https://pypi.python.org/pypi/beautifulsoup4 # Or download the file # http://www.py4e.com/code3/bs4.zip # and unzip it in the same directory as this file
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, "html.parser")
# Retrieve all of the anchor tags
tags = soup('a') => 여기 A를 Span으로 바꾸고
for tag in tags:
# Look at the parts of a tag
print('TAG:', tag)
print('URL:', tag.get('href', None))
print('Contents:', tag.contents[0]) => 요 콘텐츠를 계속 더하면 될거 같다.
print('Attrs:', tag.attrs)
인터넷에 있는 솔루션은 예전 파이썬을 활용한 것 같다..
파이썬 최신버전에서 돌아가지 않는다.

그래도 힌트를 얻었다.
밑에 부분에 카운트(count1) 함수와 합계(x)를 for문 앞에 0으로 설정한 다음
카운트는 계속 1씩 더하도록 만들고
합계는 뒤에 tag.contents를 숫자로 변환(int)한 후 계속 더해가면 된다.
count1 = 0
x = 0
# Retrieve all of the anchor tags
tags = soup('span')
for tag in tags:
count1 = count1 + 1
x = x + int(tag.contents[0])
# Look at the parts of a tag
print('Count:', count1)
print('Sum', x )
이렇게 4주차 과제도 어렵게 제출..
2번재 문제도 비슷한 방식으로 해결하면 된다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
count = int(input('Enter count - '))
position = int(input('Enter position -'))
print(url)
for i in range(1,count+1):
html = urlopen(url, context=ctx).read()
soup = BeautifulSoup(html,"html.parser")
tags = soup('a')
url = tags[position-1].get('href')
print(url)
5/6주차는 어떻게 제출해야할지 ㅠ
'Work' 카테고리의 다른 글
| [카카오뱅크] 동호회 모임통장 만들기 (0) | 2019.09.10 |
|---|---|
| [Coursera] Access to Web data week 5 (0) | 2019.06.23 |
| PP카드 - 기업은행 블리스7카드 (0) | 2019.06.21 |
| 온라인 마케터로 살아남기 - 2. 구글 닥스 결과 개인정보 정리하기 (0) | 2019.05.18 |
| 온라인 마케터로 살아남기 - 1. 구글닥스로 설문조사 신청서 받기 (0) | 2019.05.14 |