


안녕하세요 오늘은 파이썬으로 sumif 함수를 구현하는 방법을 알아보겠습니다.

파이썬으로 SUMIF 함수 구현하기
먼저 파이썬으로 sumif함수를 구현하기 위해서는 pandas 패키지 설치가 필요합니다.
판다스는 파이썬에서 데이터 분석을 위한 필수 라이브러리입니다.
| pandas는 데이터 조작 및 분석을 위한 Python 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리입니다. 특히 숫자 테이블과 시계열 을 조작하기 위한 데이터 구조 와 연산을 제공합니다. |
먼저 cmd를 입력하고 관리자 권한으로 명령프롬프트를 실행합니다.
이 후 pip 명령어를 통해서 판다스를 설치해줍니다.
pip install pandas관련된 패키지까지 모두 설치가 완료되면 이제 파이썬에서 판다스 라이브러리를 불러와야 합니다.
import 명령어로 패키지를 불러옵니다. as는 약어로 앞으로 pd를 입력하면 판다스가 사용됩니다.
import pandas as pd이후 이제 엑셀을 불러와야 하는데요.
판다스 명령어준 read_excel 을 통해서 불러올 수 있습니다.
명령어 옵션이 많지만 pd.read_excel('파일명')을 통해 불러올 수 있습니다
df = pd.read_excel('test.xlsx')| pd.read_excel( io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, mangle_dupe_cols=True) |
샘플 엑셀은 공공데이터 포탈에서 한번 가져와보겠습니다.
test.xlsx 파일의 필드명은 아래와 같습니다.
그리고 파이썬에서 엑셀의 sumif와 같은 값을 구현하기 위해서는
groupby함수를 사용하면 되는데요.
사용법은 아래와 같습니다.
공식 자습서 링크
GroupBy — pandas 1.4.2 documentation
previous pandas.api.indexers.VariableOffsetWindowIndexer.get_window_bounds
pandas.pydata.org
dfsum = df.groupby('그룹이 될 컬럼')['값이 될 컬럼'].연산()
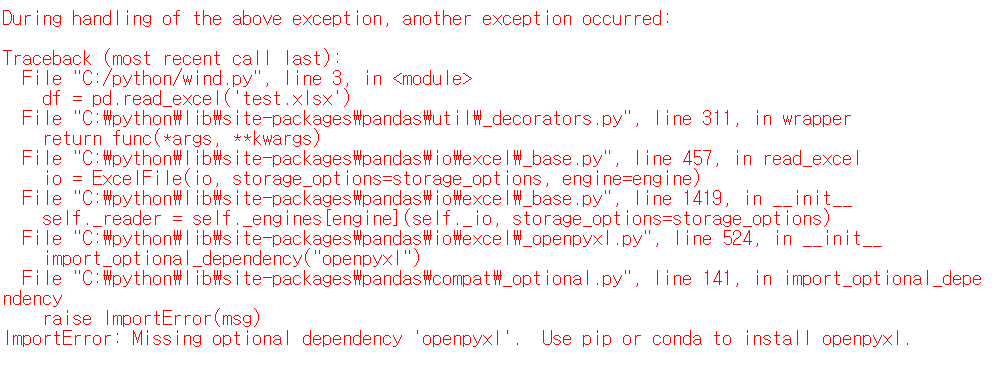
다만 해당 파일을 실행할때 엑셀 라이브러리인 openpyxl이 없다는 에러가 나옵니다.
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.
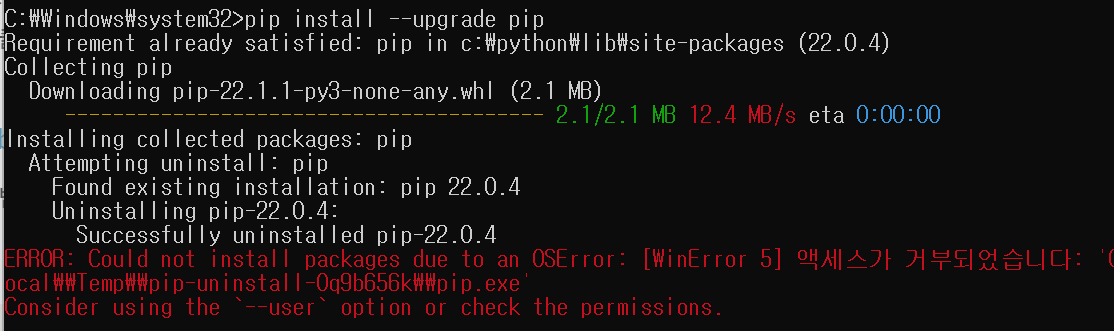
하지만 pip 업그레이드시 에러가 발생하였습니다.
| ERROR: Could not install packages due to an OSError: [WinError 5] 액세스가 거부되었습니다: 'C:\\Users\\doruz\\AppData\\Local\\Temp\\pip-uninstall-0q9b656k\\pip.exe' Consider using the `--user` option or check the permissions. |
간혹 pip 업그레이드시 에러가 발생하는데요.아래 사이트에서 get-pip.py를 다운받으시거나,
제가 블로그에 올려놓은 아래 파일을 다운로드 받으시고 실행하시면 됩니다.
https://bootstrap.pypa.io/get-pip.py
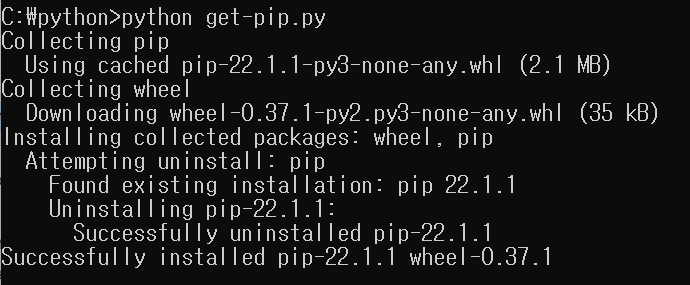
이 때에는 위의 get-pip.py파일을 다운로드 받고
python get-pip.py를 통해서 pip를 다시 설치할 수 있습니다.
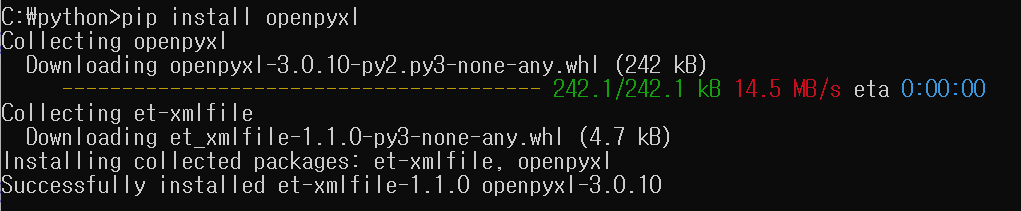
이후 openpyxl을 설치하고 다시 실행하면 정상적으로 실행이 됩니다.
명령어는 동일합니다.
pip install openpyxl
이제 정상적으로 설치가 되면, 다시 파이썬코드를 만들어보는데요.
저는 mean 함수를 이용해서 평균을 내어보았는데요.

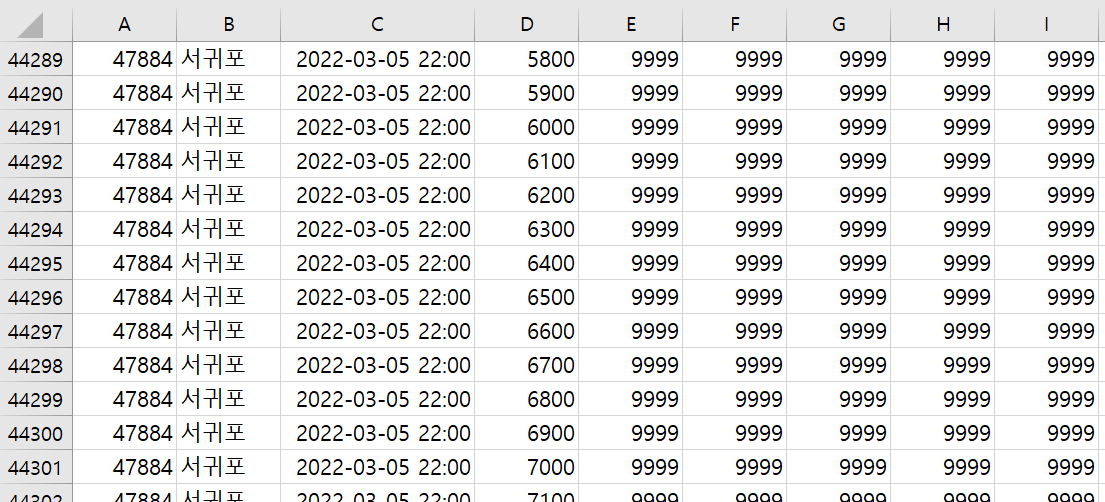
다만 군산과 파주, 서귀포는 6000m/s라는 이상한 값이 나왔는데요.
엑셀값을 실제로 열어서 분석해보니, 아마 측정이 안될 경우 9999로 표현되나 봅니다.
이 경우에는 에러가 되니, 해당 값들은 변경해야하는데요.
이렇게 하는 것을 전문적인 용어로 데이터 전처리라고 합니다.
사실 데이터분석을 하다보면 자주 만나는 현상인데요.
오늘은 자세한 분석보다는 간단하게 실무에서 활용할 수 있는 방법을 알려드리겠습니다.
이 경우에 가장 간단하게 변경하는 것은 replace함수를 이용하는 것인데요.
replace 함수를 통해서 할 수 있는데요.
이 함수 역시 자습서에서 자세한 용법을 확인할 수 있습니다.
pandas.DataFrame.replace — pandas 1.4.2 documentation
Regular expressions will only substitute on strings, meaning you cannot provide, for example, a regular expression matching floating point numbers and expect the columns in your frame that have a numeric dtype to be matched. However, if those floating poin
pandas.pydata.org
| DataFrame.replace(to_replace=None, value=NoDefault.no_default, inplace=False, limit=None, regex=False, method=NoDefault.no_default) |
df.replace(9999,0,inplace=True)라고 입력해서 값을 변경하면
마지막 옵션인 inplace는 바로 적용되는 것으로 해당 옵션을 True로 설정하지 않으면 실제 값이 변경된 것이
반영되지는 않습니다.
해당 명령어를 실행한 다음에는 정상적인 값으로 나옴을 알 수 있습니다.
물론 해당 결측치를 중간값으로 대체하거나 다양한 방식으로 대체하면 보다 정확한 값을 얻을 수 있는데요.
오늘은 단순히 0으로 설정하는 방법만 알아보았습니다.

오늘은 판다스 최초 설치부터 간단하게 sumif 함수를 구현하는 파이썬 코드까지 해봤는데요.
실제 업무에서 잘 사용하시기 바랍니다.
실제 오늘 실행한 코드는 아래에 첨부하였습니다. 참고해보시기 바랍니다.
아주 간단한 코드라 누구나 쉽게 따라하실 수 있습니다.
import pandas as pd
df = pd.read_excel('test.xlsx')
df.replace(9999,0,inplace=True)
dfsum = df.groupby('지점명')['풍속(m/s)'].mean()
print(dfsum)
'Tip & Tech > Python' 카테고리의 다른 글
| 파이썬 가상환경 만들기 (2) | 2022.06.02 |
|---|---|
| 파이썬으로 엑셀하기 - 엑셀파일 하나로 합치기 (4) | 2022.06.01 |
| 파이썬 워드 클라우드(Word cloud) 만들기 (6) | 2022.04.26 |
| 파이썬 웹페이지 표 크롤링 하는 방법(make2d) (10) | 2022.03.08 |
| 파이썬 텔레그램 챗봇 만들기 - 인포메시지 및 명령어 설정하기 (10) | 2022.02.23 |