

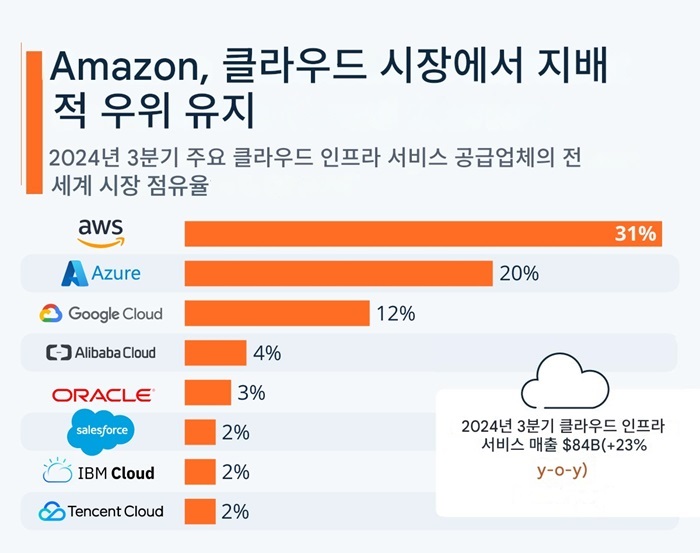
최근 정말 전산 장애가 너무 광범위하게 발생하는데요. 오늘 전세계의 31%의 점유율을 가진 AWS가 장애가 나서 전세계 서비스가 동시에 다운되었습니다.
AWS란?
AWS(Amazon Web Services)의 약자입니다. Amazon Web Services(AWS)는 전 세계적으로 분포한 데이터 센터에서 200개가 넘는 완벽한 기능의 서비스를 제공하는, 세계적으로 가장 포괄적이며, 널리 채택되고 있는 클라우드 서비스라고 할 수 있습니다.

AWS는 클라우드 컴퓨팅을 통해 인터넷을 기반으로 컴퓨팅 성능, 데이터베이스, 스토리지, 애플리케이션 등 IT 리소스를 온디맨드 방식으로 제공합니다. 사용자는 필요한 만큼만 리소스를 사용하고, 이에 따라 비용을 지불하는 종량제(pay-as-you-go) 모델을 활용할 수 있습니다
즉 전통적인 국가정보자원관리원의 경우 실제적인 물리 서버와 네트워크 등을 직접 관리하는데요. 클라우드 서비스에서는 이를 클라우드 서비스 회사가 제공합니다. 즉 분업화라고 할 수 있는데요. 그 단계에 따라 IaaS, Paas, SaaS로 나뉩니다.
2015.11.21 - [Tip & Tech/Computer] - [OpenStack] What is OpenStack
[OpenStack] What is OpenStack
[OpenStack] What is OpenStack 준비물 : EXIN 시험 등록 연관 게시물 : 이번에는 EXIN에서 나오는 Foundation Certificate in OpenStack Software에 맞추어 FOSS 자격증 취득을 하면서 공부한 OpenStack에 대해서 알아보도록
dorudoru.tistory.com
즉 복잡한 서버 관리를 외부에 맡기고 회사는 본인의 서비스만 제공하는 형태로 운영하는 것인데요. 거기다가 매번 한번에 서버를 큰 돈을 주고 구매하지 않고 말그대로 사용한만큼 지불하게 되서 큰 투자비용을 절감할 수 있습니다. 다만 이와 같이 클라우드 회사가 장애가 나면 전체 서비스가 장애나는 단점을 지니고 있습니다.
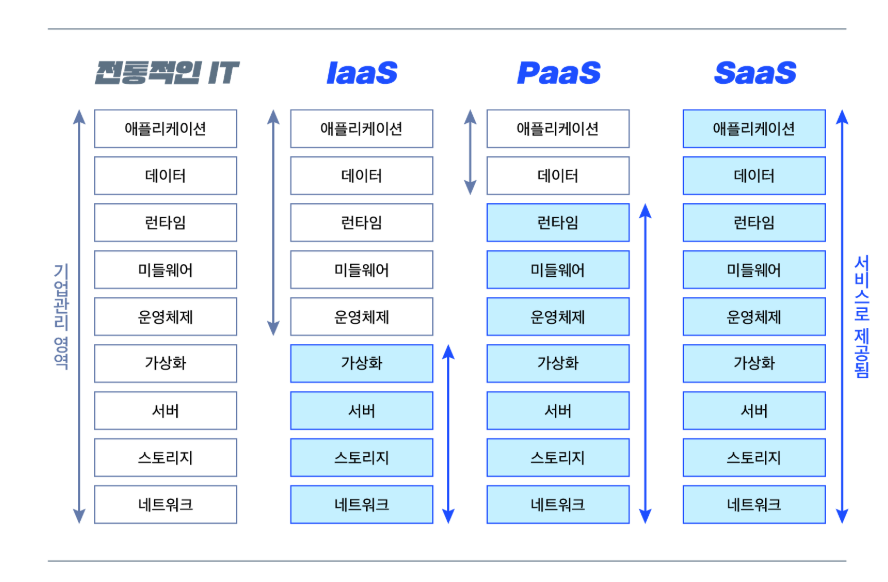
즉 고정비가 들고 복잡한 하드웨어 구성을 클라우드 업체에 맡겨 빌려쓰는 형태로 쓰는것인데요. 최근 가전을 구입하지 않고 렌탈해서 쓰는 것과 동일한 이치라고 생각하시면 됩니다.
AWS 장애
클라우드 장애는 전 세계적으로 수많은 온라인 서비스에 영향을 미치기 때문에 큰 이슈가 됩니다. 최근 MS의 클라우드 스트라이크 장애로 전세계 서비스가 다운되는 문제를 겪었었는데요.
2025년 10월 20일에 AWS가 장애가 났습니다. AWS는 그래도 장애 결과를 빠르게 공지하였는데요.

장애 내용: 미국 동부 버지니아 북부 지역(US-EAST-1 리전)의 게이트웨이 또는 DNS(도메인 이름 시스템) 해석 오류 문제로 인해 다수의 AWS 서비스에서 오류율과 지연(latency)이 급증하는 장애가 발생했습니다.
예전 페이스북 장애도 DNS 관련 장애였는데요. DNS는 도메인 네임 서버의 약자로 말 그대로 우리가 크롬과 같은 웹 브라우저에 www.naver.com으로 사람이 인식할 수 있는 도메인(영어)로 적으면 이 주소를 실제 컴퓨터가 사용하는 IP(숫자)로 변환해주는 역활을 하는 서버입니다. 즉 이 다이너모 DB(DynamoDB) 서버가 죽으면서 사람들이 요청하는 서버를 찾지 못해서 장애가 발생한 것입니다.
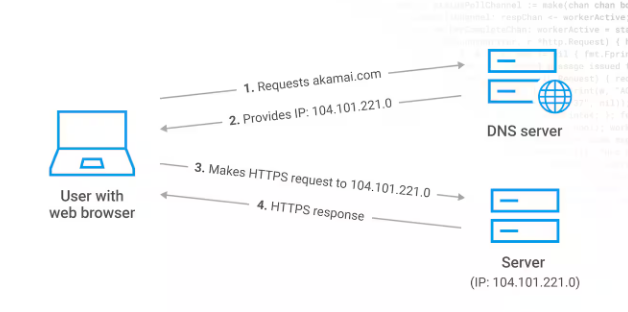
2021.10.06 - [Tip & Tech/IT] - 페이스북 장애와 BGP 그리고 DNS
페이스북 장애와 BGP 그리고 DNS
어제 페이스북 계열인 페이스북과 인스타가 6시간이 넘도록 먹통이 되었습니다. 최근 들어 구글 네이버 등 국내외의 IT 기업의 서비스 다운이 자주 발생하는 것 같은 느낌인데요. 이번 장애는 BGP
dorudoru.tistory.com
보다 자세한 내용은 위 포스팅을 참고해보세요.
영향: 아마존 자체 서비스(아마존닷컴, 알렉사)는 물론, AWS를 사용하는 퍼플렉시티, 스냅챗, 듀오링고, 슬랙, 로블록스 등 글로벌 주요 서비스들이 약 3시간 동안 접속 불가 또는 기능 마비 상태를 겪었습니다. 국내 서비스 중에도 AWS를 이용하는 일부 서비스가 영향을 받았습니다.
특히 이번 사고의 경우 AWS가 점유율이 31%나 되다보니 사실상 1/3의 서비스가 먹통이 된 것입니다. ChatGPT와 연계된 Azure의 점유율이 많이 올라왔지만 아직 20% 수준이네요. Oracle의 주가는 엄청 올랐지만 클라우드 서비스는 아직 점유율이 미미합니다.
과거 주요 AWS 장애 사례
2021년 12월: 북미(US-WEST-1, US-WEST-2) 서버에서 통신 장애가 발생하여 트위치, 디스코드, 넷플릭스, 리그 오브 레전드 등 다수의 플랫폼에 영향을 미쳤습니다.
2020년 11월: AWS 장애로 어도비, 오토데스크, 야후 플리커 등 다수 고객사의 온라인 서비스에 장애가 발생했으며, 재택근무 확대로 인해 일반 기업의 전산망까지 마비되는 사례가 증가했습니다.
클라우드 장애 예방
이러한 장애를 막기 위해서는 클라우드 서비스 역시 이중화를 해야하는데요. 다만 실제 제가 서비스를 운영할 때도 AWS와 Azure를 병행해서 운영해야 하는데요. 다만 두 서비스간 호환이 안되는 부분이 많이 있어서 이 부분을 포팅하는게 쉽지 않습니다.
즉 비용이 엄청나게 많이 드는데요. 특히 이종간 클라우드 다중화는 기술적으로도 해결해야 하는 이슈들이 있습니다. 이번 장애를 통해서 클라우드 이종 시스템간 이중화라는 문제를 또 해결해야 하는데요. 아마 대부분의 기업이 이번 사태를 겪고도 즉시 조치하기에는 비용 이슈가 너무 커서 또 동일한 장애가 발생할 것으로 예상됩니다.
MS 클라우드 스트라이크 사태 이후에 이중화 한다고 회사들이 말은 했지만 실제적으로 이중화를 한 곳은 손에 꼽았기 때문입니다. 정부 역시 L4 스위치 장애 이후에 이중화를 한다고 했지만 하지 않았고 결국 구가정보자원관리원 화재로 모든 서비스가 다운되는 초유의 사태를 보여주었습니다. 이중화만 했더라면 아무 문제 없었을 텐데 그 누구도 이중화를 하지 않았습니다.
2025.09.27 - [News] - 대전 국가정보자원관리원 화재로 119 정부24 등 서비스 다운
대전 국가정보자원관리원 화재로 119 정부24 등 서비스 다운
정부 전산시스템이 있는 대전의 국가정보자원관리원에서 배터리 화재가 발생해 정부 전산서비스가 대규모로 마비됐습니다.대전 국가정보자원관리원 화재행정안전부와 소방청 등에 따르면 이
dorudoru.tistory.com
정말 기본적인 것인데 이중화도 안하고 이렇게 서비스를 운영하는 것이 트렌드가 되는 것 같아 씁쓸하네요.
해킹 사건도 많고 이런 장애도 많아서 서비스 회사의 고민이 많겠습니다.
'News' 카테고리의 다른 글
| 미-중 희토류 분쟁 이슈 총정리 (0) | 2025.10.27 |
|---|---|
| AI는 일자리를 정말 없애는가? (3) | 2025.10.24 |
| SK쉴더스 해킹 허니팟이란? (0) | 2025.10.20 |
| 유튜브 접속 장애 (0) | 2025.10.16 |
| 캄보디아 웬치 대학생 고문 사망사건 (0) | 2025.10.15 |