요즘 개인적으로 Python을 하나씩 배워가고 있는데요.

저처럼 코딩에 익숙하지 않아도, 쉽게 만들어진 코딩 Tool이라서 원하는 기능을 쉽게 만들수 있는점이 참 좋네요.
오늘은 그중에서 Python으로 자주하는 웹크롤링을 한번 연습해 보고자 합니다.
너무나 잘 정리된 페이지가 있어서 여기를 보고 많이 참고하였습니다.
자연어처리 개발자 님의 페이지 : chicken-nlp.tistory.com/4
웹 크롤링이란?
위키의 설명에 따르면,
웹 크롤러(web crawler)는 조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램이다.
라고 정의되어 있습니다. 즉 자동으로 싸이트를 탐색해주는 인터넷 매크로(?)같은 프로그램이라고 보시면 됩니다.
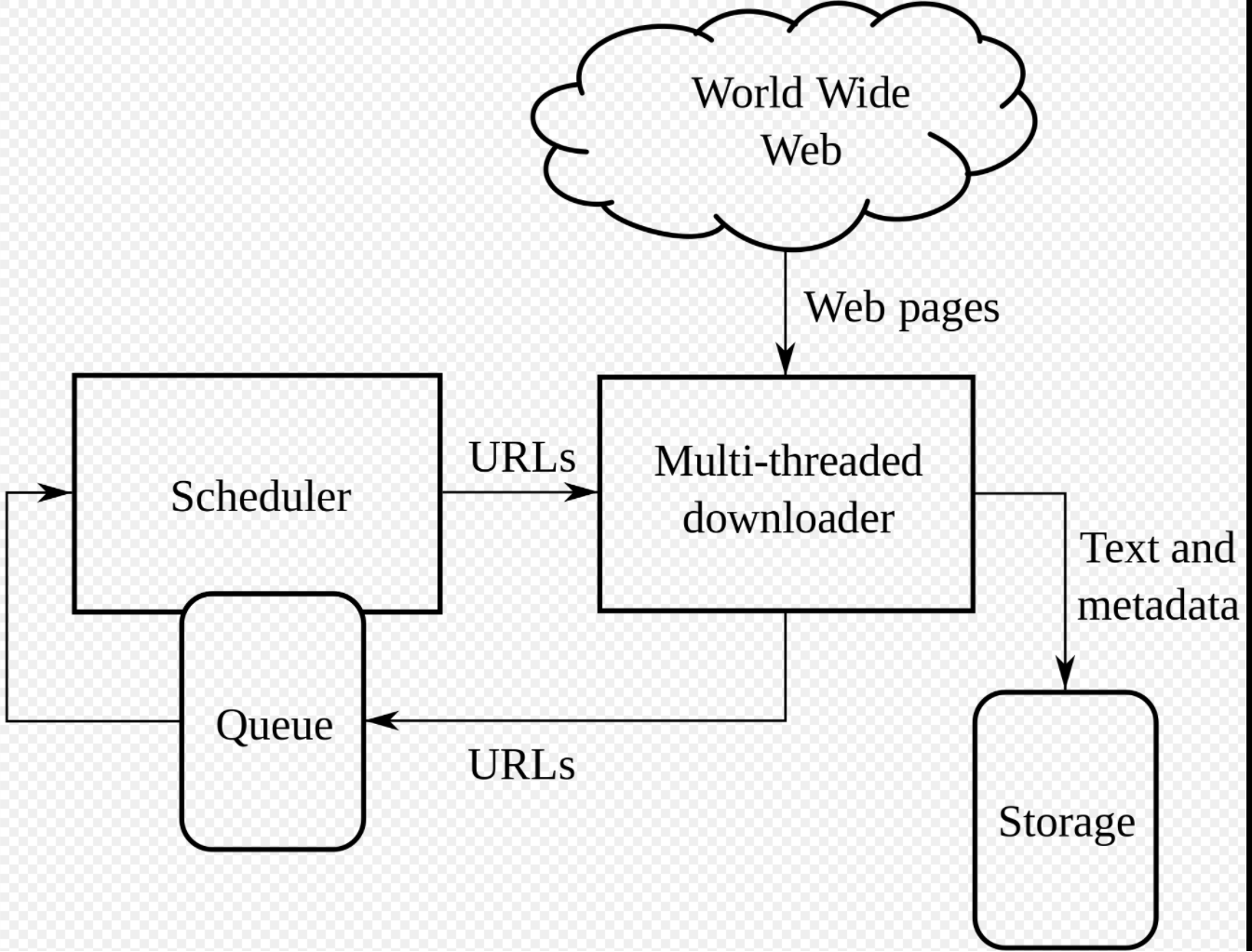
웹 크롤링하기 1. 페이지 분석
웹크롤링을 하기 위해서는 먼저 크롤링 하고자하는 페이지가 어떻게 구성되어 있는지부터 확인해야 합니다!
요즘 한국시리즈로 핫한 프로야구 갤러리를 들어가보겠습니다.
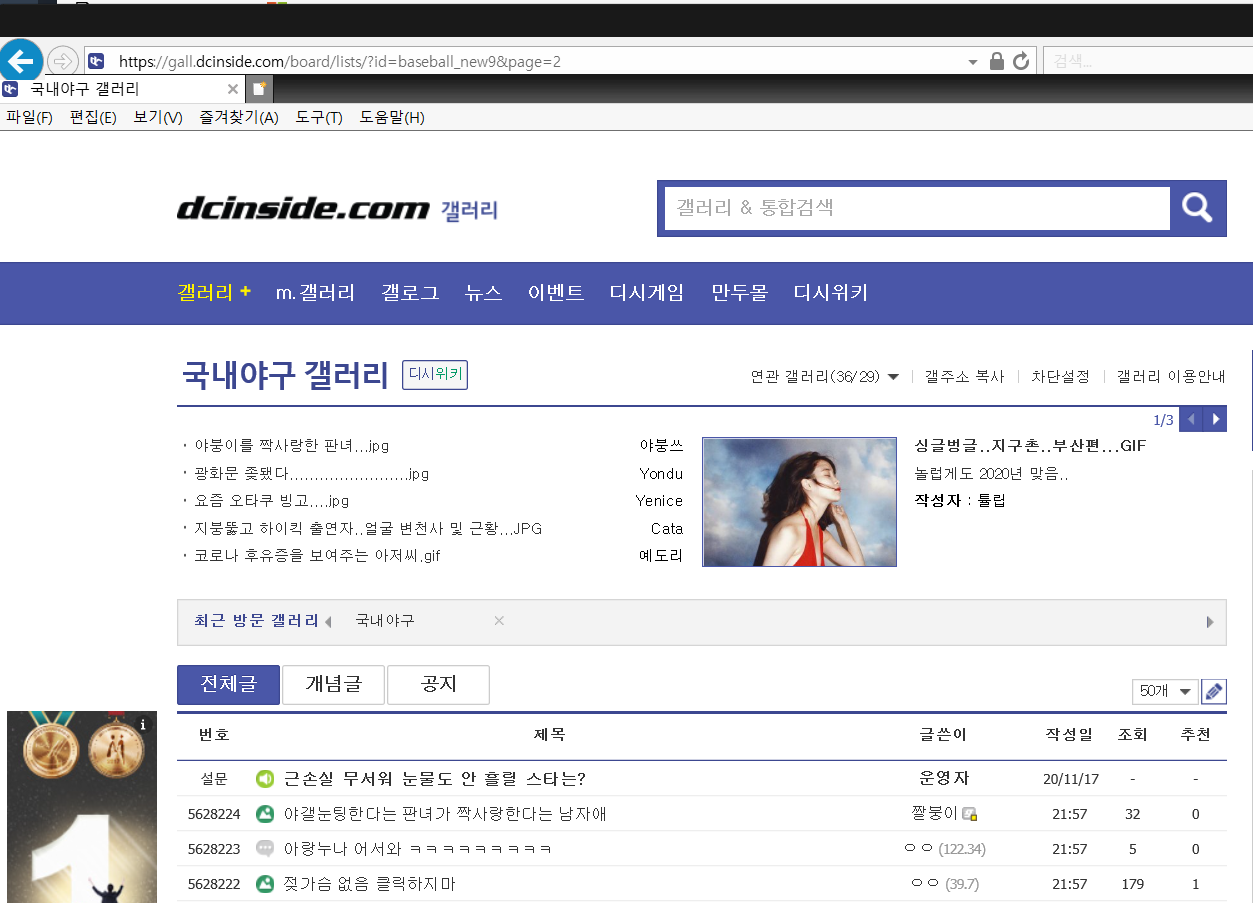
gall.dcinside.com/board/lists/?id=baseball_new9&page=2
웹페이지의 구조가 아래와 같이 되어있습니다.
앞에 gall.dcinside.com/board/lists/까지는 변하지 않고 뒤에 ?id 로시작하는 파라미터가 변경이 됨을 알 수 있습니다.
여기에서 id는 갤러리별 구분자이며, page는 해당 갤러리의 페이지입니다.
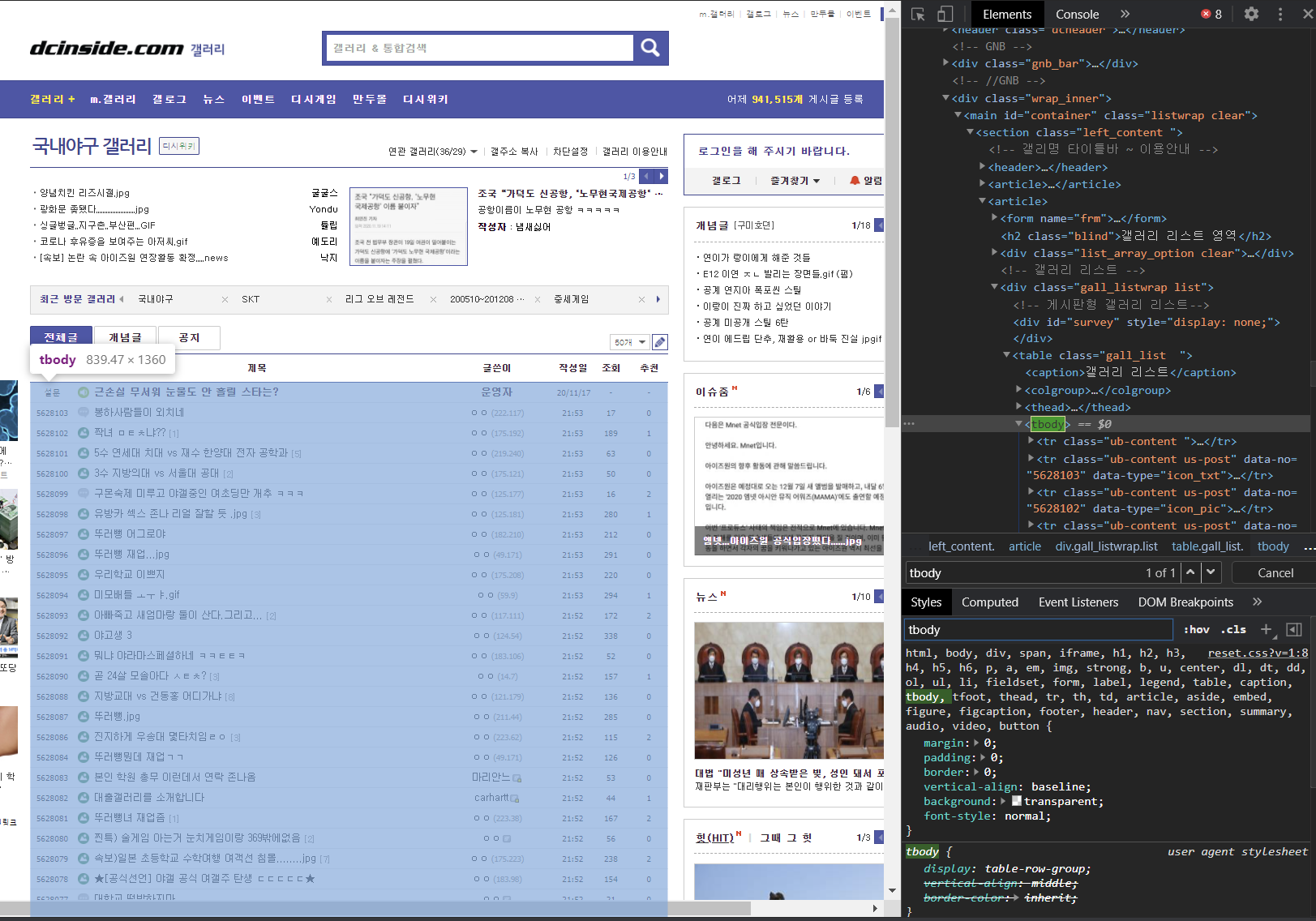
그리고 크롬에서 해당페이지를 들어가서 F12(개발자모드)를 통해서 페이지 구조를 살펴보면
<tbody> 테이블안에 게시판이 들어있음을 확인할 수 있습니다.
인터넷의 페이지등을 참고해서아래와 같은 형식으로 코딩하였습니다.
디시인사이드 싸이트중에 비어있는 사이트도 많아서 예외를 많이 처리할수 밖에 없었습니다.
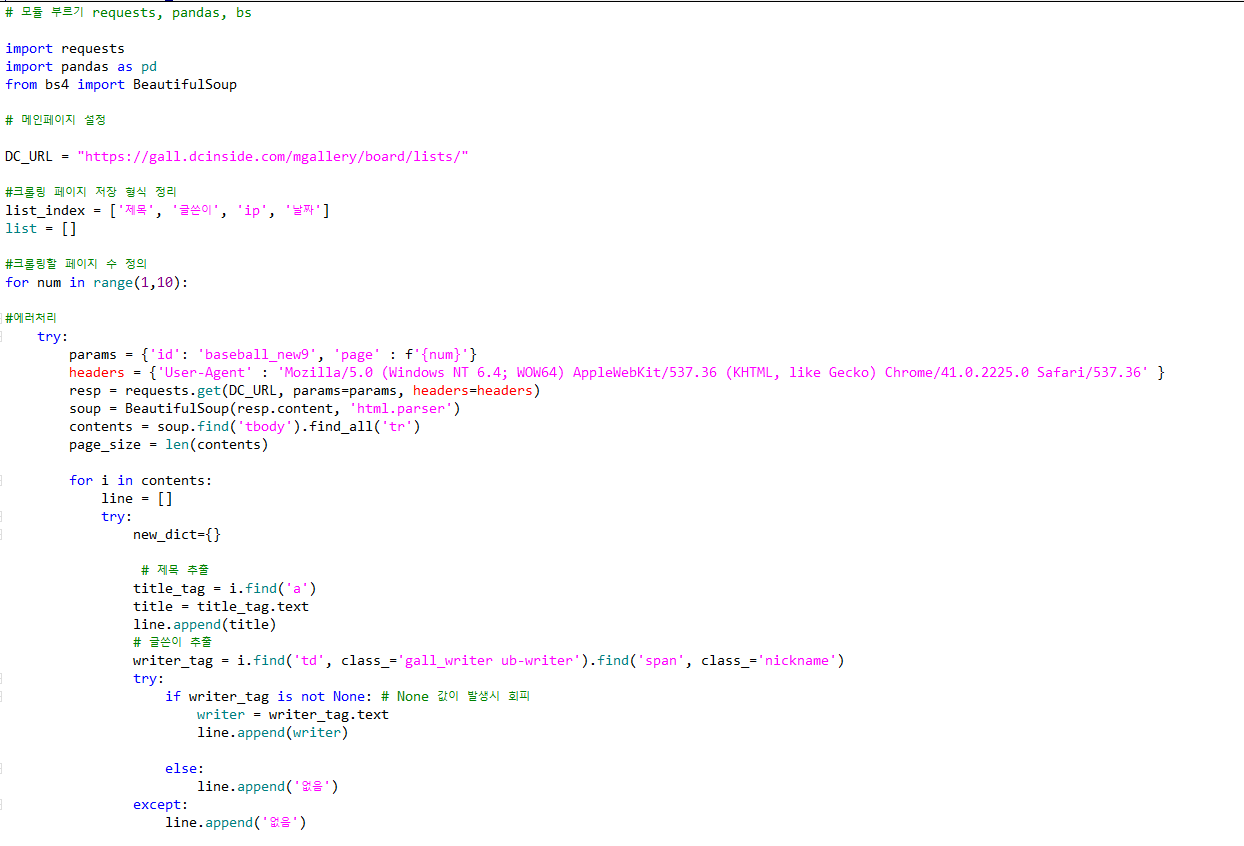
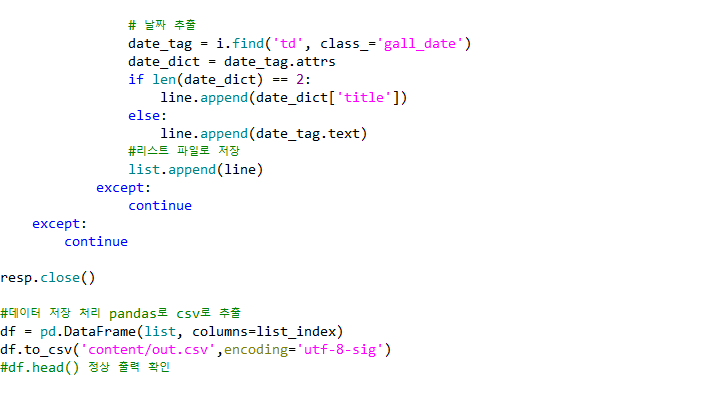
마지막에는 pandas를 활용해서 csv파일로 만들어서 출력하였습니다.
이번 코딩을 해보면서 많은 것을 배울 수 있었는데요.
append를 통해서 요소값에 추가를 하고, pandas를 통해서 데이터를 표형식으로 변환하며
csv로 추출할수 있습니다.
나중에 좀더 공부해서 더 잘 동작하는 코드로 만들어봐야겠네요.
다들 파이썬 열공하시길~
'Tip & Tech > Python' 카테고리의 다른 글
| 파이썬 기초 문법 3일차 - Numpy (4) | 2021.09.03 |
|---|---|
| 파이썬 기본 문법 강의 2일차 - 제어문으로 로또 게임 만들기 (8) | 2021.09.02 |
| 파이썬 기본 문법 강의 - 1일차 (9) | 2021.09.01 |
| 파이썬으로 네이버 웹툰 웹크롤링 하기 (0) | 2021.04.05 |
| 파이썬으로 네이버 스포츠 농구 일정 크롤링 하기 (9) | 2021.02.17 |
